零基础实现高质量数据挖掘(策略分析篇)
/title2.jpg)
1 简介
1.1 上手难度
参考:零基础实现高质量数据挖掘(数据分析篇)- 1.1 上手难度
零基础?某些意义上来说,这个标题是有一些“标题党”了,有些朋友可能会抬杠说不是“零基础”吗,怎么点进来一看还是需要会写python,那我不会写python是不是就不用看了?如果我python已经很精通做得很好了是不是也不用看了?而且如果不会学了也不一定学得会,投入产出比太低了是不是不太划算?
目前“零基础”解决方案是不需要学习太多python语法的,基本上是类似“命令行”的参数化解决方案,全部需要写的可能也几句代码来形成一份通用的“配置文件”,运行后实现所有分析内容自动写入报告后输出,虽然说起来要写代码却基本上能实现“零基础”入门,
从历史培训实践来看,基本没有学习难度,小白也能快速上手,投入产出非常惊人,具体案例在本章的最后一节1.4 案例展示中会进行演示
策略分析的可见本节1.4 案例展示部分
1.2 业界对比
参考:零基础实现高质量数据挖掘(数据分析篇)- 1.2 业界对比
优势是什么?目前数据挖掘类的项目,无论是营销、风控还是别的场景,工具链都非常丰富,除了python还可以用SAS\R\SPSS等等,不想写代码还可以买市面上的商用模型平台,例如阿里的PAI平台,或者Salford Systems的SPM等等,都不用写代码,直接拖拉拽点击就行,为什么我还要使用这个工具呢?
针对以上问题,按市场行情和业界实践,这里按类别梳理了对比的表格:
平台类解决方案(PXX平台、图X平台等) 单机商用解决方案(SXX/SXXX等) 直接使用开源模块(c/c++/python/java/r等) 我的解决方案(基于开源模块二次开发与封装) 价格 高,主要面向企业用户 中,部分面向个人用户 无,开源 低,主要面向个人用户 操作难度 低,面向非编程人员,主要使用点击和拖拉拽 中,可使用点击和拖拉拽,或自定义脚本开发 高,主要面向编程人员,直接撰写代码需要控制大量细节 中,参数化封装配置文件,可融合自定义脚本开发 分析颗粒度 粗糙,基于组件封装不可进行细节调整,部分平台能支持较为细致的代码融合开发 一般,页面点击或脚本自定义 细致,基于源代码开发 细致,模块化参数控制或基于源代码开发 开发成本 中,拖拉拽点击配置,一般可加载复用,如涉及脚本自定义开发则开发成本较高 中,拖拉拽点击配置,一般可加载复用,如涉及脚本自定义开发则开发成本较高 高,debug开发成本不可控制,且不同场景通用性较低 低,参数化封装后,配置文件一次配置可多次重复使用 硬件要求 高,一般需要服务器部署配置各类服务项 中,一般单机点击安装包即可 低,基于源代码任意安装和开发 中,单机安装conda/python配合pip即可 一体化程度 高,通常能同时支持特征生成和模型部署等全流程操作 中,一般不包含特征工程,可导出模型文件和分析结果 低,基于源代码自行开发 中,不包含特征生成,针对分析本身,导出对应的模型文件和分析结果 扩展性 低,一体化平台一般不支持非官方自定义扩展 中,不支持扩展或官方插件扩建需要加钱,或只能使用特定脚本扩展 高,可基于任意生态任意扩展融合 高,可基于python生态任意扩展融合 我的解决方案非常适用于以下几类场景:
场景示例
- 我既不想写代码,也不会写代码,我就想知道数据效果怎么样
- 按规矩的方式仔细做分析要好久,我想知道有没有深入分析的必要性
- 重头到尾整合报告太累了,我需要一个工具一键生成常见的报告
- 代码我都会写,原理我也都懂,只是现在没时间慢慢搞
- 学过一遍之后剩下的都是重复操作,我想避免无意义的内卷,留点时间干别的
简单总结来说,我的解决方案可以在较低的开销下,参数化模块化常用分析结果,帮助分析师绕开繁琐重复的日常操作,可快速生成分析结果并反复参数化调优,在维持高质量分析的基础上大幅降低分析成本
1.3 数据适用性
参考:零基础实现高质量数据挖掘(数据分析篇)- 1.3 数据适用性
支持的数据量?现在都是大数据时代,如果数量太大python处理的了吗?使用python是不是不合适?
如果是数据量足够大的情况下(PB起步,淘宝、微信,或流水日志等等),一般也没有太多可以选择的空间,基本都是各类hdfs分布式数据库进行存储和操作,例如阿里的odps、常见的hive\hadoop\spark套件等等,这个维度也不是各类单机分析软件的处理领域,
从业界实践来看,一般很多分析确实没有那么大的数据量,即使数据量真的很大,在具体设计方案上和实施层面中也有很多解决的办法和优化的方式,举例如下:
数据量较大时的处理案例
- 从统计学抽样方式进行数据切片并将一次任务转化为多次进行数据降维
- 较为严格的在时间层面上定义观察期和表现期来缩小可用数据范围
- 较好的进行前置分析,对数据进行合理的预分群等进行样本拆分
- 前置spark等分析工具预处理降低后期细颗粒度分析时的数据宽度
- 实现内嵌spark等底层分布式解决方案,如xgboost和lightgbm等
- 直接基于分布式服务器环境搭建jupyterhub等工具,内存理论上无上限
1.4 案例展示
还是使用一样的案例数据文件和同样的jupyter环境搭建、python环境管理方式,代码的数据读取和加载方式也和零基础实现高质量数据挖掘(数据分析篇)- 1.4 案例展示中的一样:
import pandas as pd # 导入我自定义的模块 import sys sys.path.append("./code_libs") import alpha_tools as at # 导入数据 df_ = pd.read_csv("application_record.csv") df_response = pd.read_csv("credit_record.csv") # 添加“年龄”变量 df_['Age'] = -(df_['DAYS_BIRTH']) // 365 # 定义标签和数据 df_["target"] = df_["ID"].map(df_response.groupby("ID")["STATUS"].apply( lambda x: 1 if ({"2", "3", "4", "5"} & set(x)) else 2 if ({"1"} & set(x)) else 0)) df_data = df_[df_["target"].notnull()] # 划分数据集 from sklearn.model_selection import train_test_split df_train, df_test = train_test_split( df_data, test_size=0.3, stratify=df_data["target"], random_state=42) # 进行分析 at.Analysis.data_flow(df_train, "./数据分析demo/v1/v1.xlsx", test_data=df_test, response="target")
默认会基于lightgbm进行树模型建立,并解析树规则按规则性能排序来进行策略搜索,样例代码如下:
at.Analysis.tree_flow(
df_train, "./策略分析demo/v1-lgb/v1-lgb.xlsx", test_data=df_test,
# 目标定义 & 切片定义
response="target", split_col_name="birth_year", use_train_time=True,
exclude_column=["ID", "DAYS_BIRTH"], # 多变量分析时,DAYS_BIRTH会干扰Age的分析
add_info="ID", # 主键添加
# 默认参数为lgb
# model_type_path="lightgbm.sklearn.LGBMClassifier",
)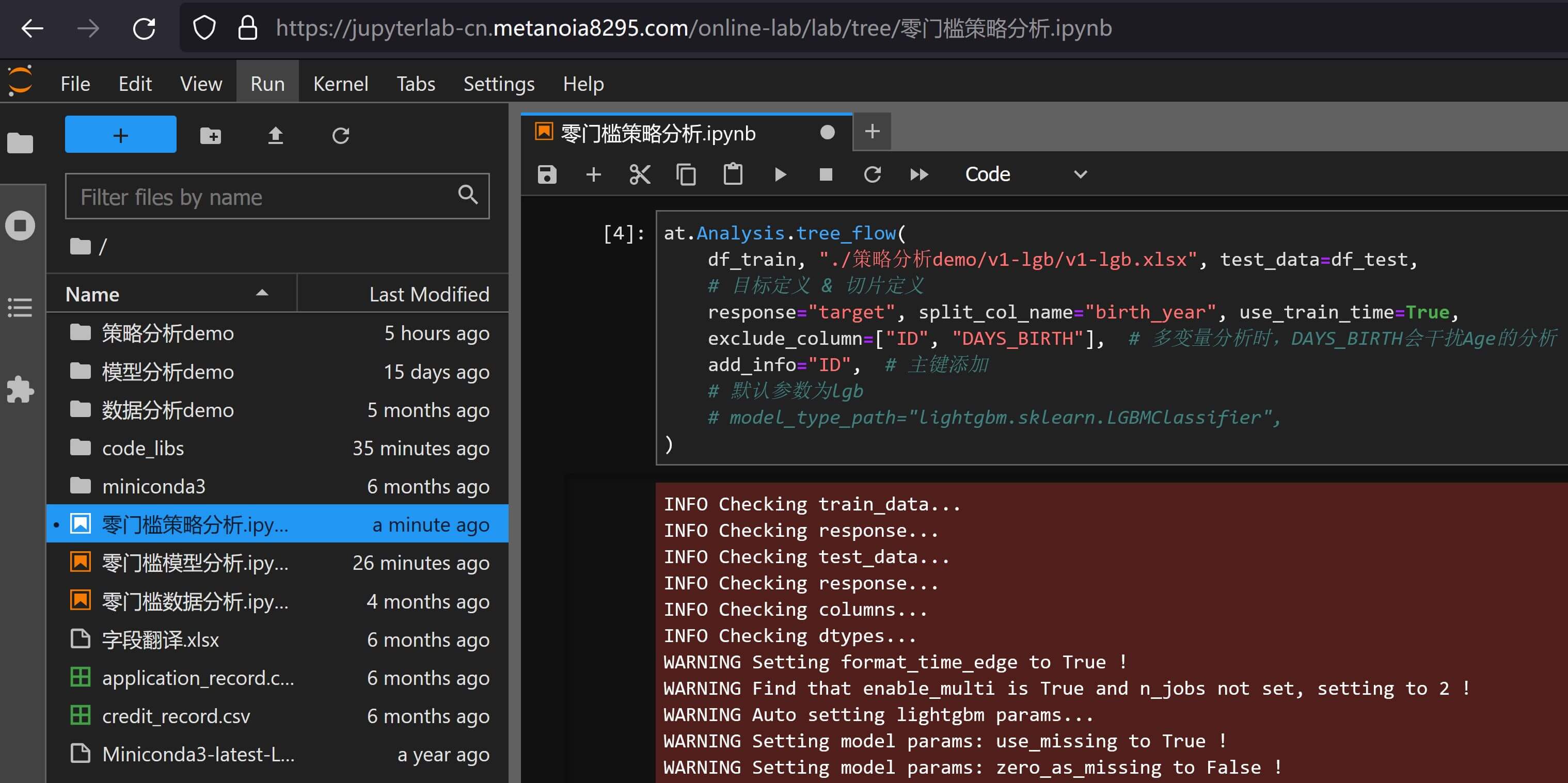
lightgbm规则搜索样例可得策略分析报告v1-lgb.xlsx,其中包含推荐的策略、树模型结构、树模型部署文件等,另外还提供可视化文档策略分析报告v1-lgb.pdf,其中包含详细的树结构绘图,那为什么需要模型策略化呢?
前面几篇文章介绍到的数据化和模型化,在实战中至少有以下几个问题点:
- 模式较重:虽然基于模型参数搜索和模型交叉矩阵等已经可以实现基于模型分数段和多数据源的综合决策,但模型部署仍然需要一整套工程化环境来执行
pkl、pmml或sql等模型文件,整体链路较长且模式较重,尤其是针对刚起步的小公司或小项目,见效慢且投入不低 - 可解释性存疑:虽然基于指标和模型总分的快速监控没有技术层面的问题,但是再细致的监控也绕不开多数模型可解释性的问题,也不一定能解释模型性能的衰减和不稳定,这也是为什么即使是各个大厂,也很难绕开模型风险和模型验证等元素,能绕开的也只能是低试错成本的中小项目,这些步骤也加重了整体链路的冗余性,这也是金融行业评分卡模型经久不衰的原因之一
- 有效数据瓶颈:无论是单变量分析,还是多变量分析,只要需要预测的目标是少数,有效的数据也一定是少数,还需要排除数据之间的相关和互斥,当然也可以使用分数据源模型融合等技术不断逼近有效数据性能的天花板,但这个过程投入巨大且结果上来看效果有限,同时还面临着单变量筛选太严格导致不能较好的挖掘多个弱变量之间的非线性关系的问题
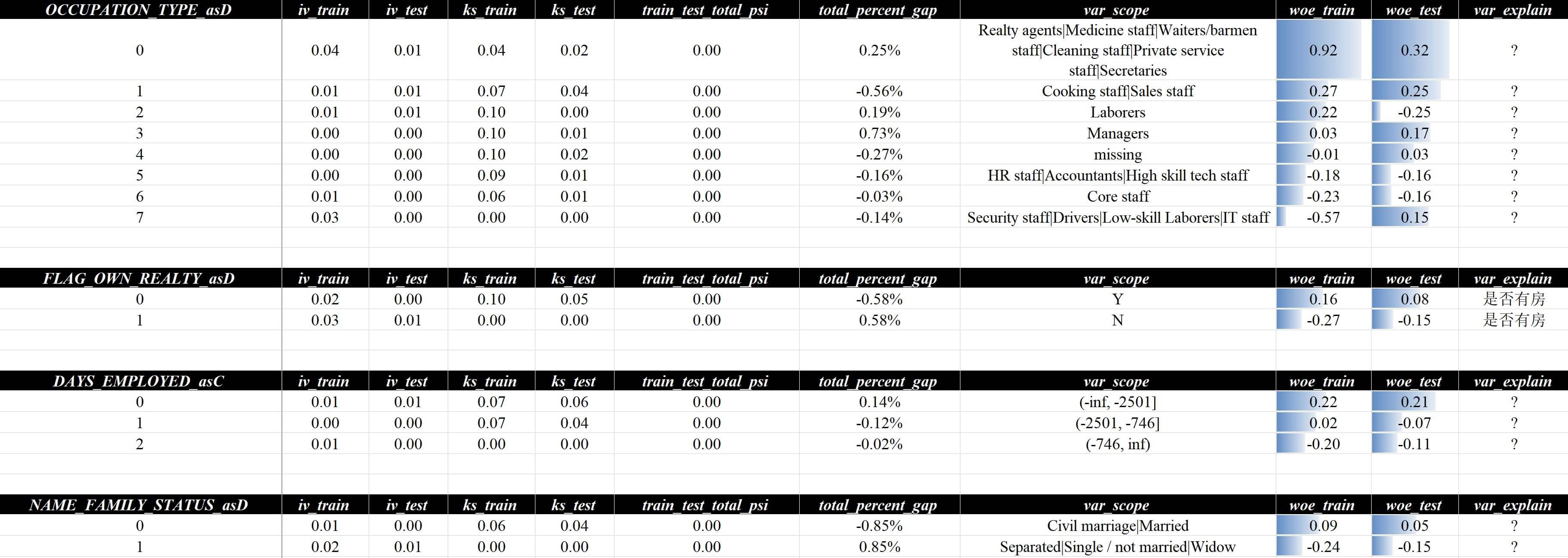
目前实现的自动化策略挖掘,能相当程度缓解上面提到的几个问题,比如从策略分析报告v1-lgb.xlsx中的规则评估 - 负向规则 - 汇总页面可以看到,前两条推荐的负向规则虽然命中较少,但坏客户命中率都很高,而且无论是分布还是有效性都较为稳定:
上述两条规则在数据层面的含义:
- 婚姻状态为单身、未婚或丧偶,且家庭成员数量>=2,且无子女或子女数量<=1
- 婚姻状态为非(单身、未婚或丧偶),且家庭成员数量<=1,且年龄>65
在业务含义层面的含义:
- 没有较好的家庭支持,但却有较重的家庭负担,子女数量还较少,推测需要赡养老人、有家庭成员不工作或没有稳定的收入来源
- 虽然有家庭但成员较少且自身年龄较大,推测无子女或少子女,整体现金流有限
针对模型化的问题,所具备的优点:
- 模式轻量:挖掘规则和部署规则完全独立,虽然指标开发、规则部署的开发量不可避免,但对比模型部署的流程轻量很多
- 强可解释性:树模型天然的树结构,使得挖掘的规则在控制树深度的前提下具备了极强的可解释性,上面两条案例规则的解读就是最好的证明
- 最大化数据效果:首先树模型能融合多变量效果,其次梯度提升等算法的思想完美符合策略增量挖掘的需求,能很好的捕获数据之间的弱关联,也能基于已有的模型分挖掘互补策略,最大化数据效果,且支持基于业务经验的校验和补充
上述案例还是未经仔细调参的策略挖掘的结果,可想而知,经过仔细调试后的策略挖掘无疑会做的更好,可以说在业务起步阶段或项目早期,目前的策略挖掘模块能快速上手,实现数据含义和业务直觉的完美融合,低成本达到生产级高性能产出
2 基础定义
与零基础实现高质量数据挖掘(数据分析篇)- 2 基础定义中的介绍基本一致,
数据挖掘子模块实在太多了,按建模目标可以分为:分类、回归、聚类问题,按主题还可以分为:营销、风控、欺诈、图像识别、文本翻译、自然语言处理,而其中的分类也可以有二分类、多分类,不同的主题有不同的分析链路和分析范式,如果没有领域志向,很难把分析元素固定和泛化,从上面的案例也可以看到,本文涉及的参数化工具包主要是针对二分类问题的,业界常用的场景有金融领域的风险识别、营销响应、欺诈识别等等,这里都按风险识别进行举例
差异部分和背后的逻辑请参考1.4 案例展示部分
2.1 数据模型定义
数据定义方面,和零基础实现高质量数据挖掘(数据分析篇)- 2.1 数据定义中必填项完全一致:
主要需要定义的必填项是
train_data和output_name参数,其他参数包括test_data等全都是选填项,# 必填项 # train_data 必填,训练集,pd.DataFrame数据类型 # output_name 必填,绑定的各类输出的基本名称,需要以.xlsx结尾
基础定义上,和零基础实现高质量数据挖掘(模型分析篇)- 2.1 数据模型定义中基本一致,参数还要更精简一些:
基础定义上则是基本一致:
# 基础定义 # test_data 选填,默认None,对应的测试数据或验证数据 # task_type 选填,默认"binary",任务类型,可条件性修改 # exclude_column 选填,默认None,排除的数据的列,支持str和list # flow_data_type 选填,默认"WOE_",可选"ORI_",数据选取的关键字 # xlsx_must_exists 选填,默认False,output_name关联的excel不存在时会报错 # sample_weight_name 选填,默认None,输入后来指定使用某一列的数值调整样本权重 # auto_convert_dtype 选填,默认True,将train_data和test_data每列数据类型转化一致 # search_recover_path 选填,默认True,当data为None时候,是否在搜索时包含recover路径 # slient_performance_warning 选填,默认True,建模时忽略pd.errors.PerformanceWarning的warning其中
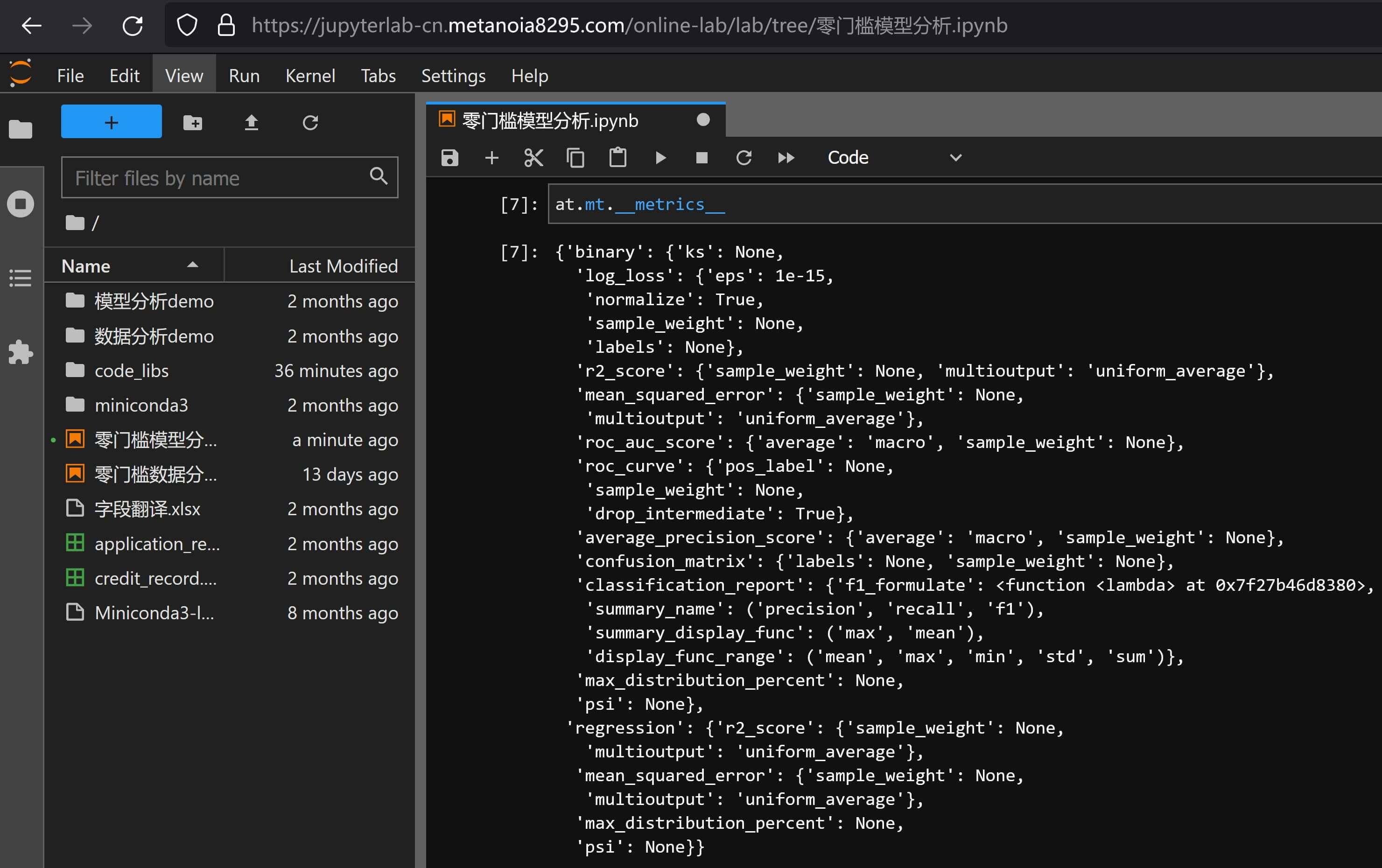
task_type支持"binary"和"regression",如果是"regression"时不会启用和检测标签定义"binary"的取值情况,可用通过__metrics__全局参数来查看分类回归在评估方式上输出的差异:分类回归评价差异
因为涉及到独立决策分析,本模块的task_type只支持"binary",同时删除了:flow_data_type和xlsx_must_exists,
而在模型基础定义环节,和零基础实现高质量数据挖掘(模型分析篇)- 2.1 数据模型定义中也是基本一致:
而有关建模定义的最基本参数主要如下:
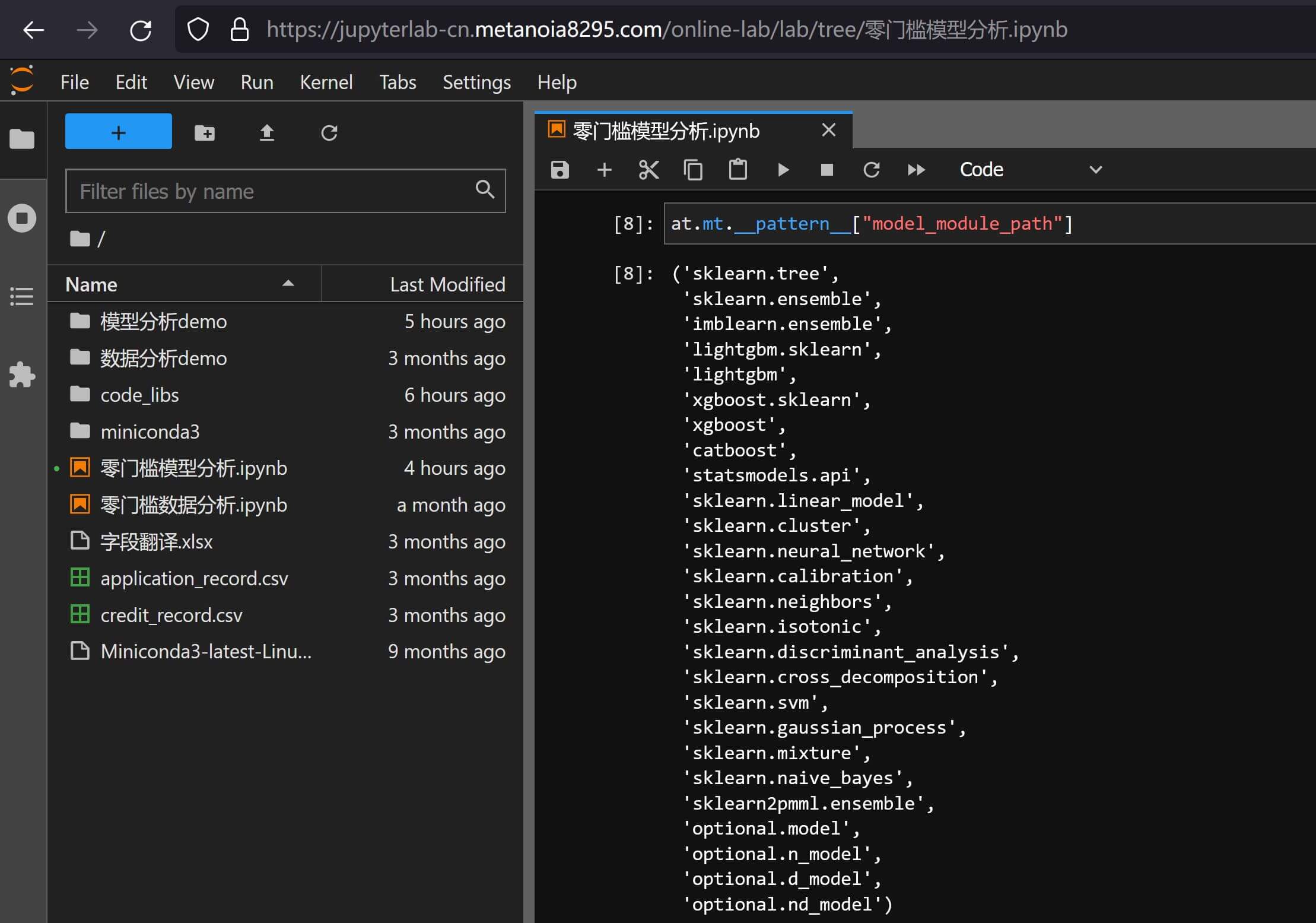
# 模型定义 # model_type_path 选填,默认"statsmodels.api.Logit",采用标准逻辑回归 # auto_set_params 选填,默认True,按预处理和模型特性等自动填充模型参数 # auto_resize_score 选填,默认True,检测分数与目标关系,部分评估进行尺度调整 # slient_model_warn 选填,默认True,忽略训练预测时,因调用三方模块生成的消息首选主要通过修改
model_type_path来指定使用不同类型的模型,支持的模型范围可以通过全局定义来查看,目前支持的范围如下:参数化建模支持范围
差异点在于删除了参数auto_resize_score,而且model_type_path的默认参数改成了"lightgbm.sklearn.LGBMClassifier",当然model_type_path的范围也缩小到了常见的树模型,一般来说足够使用: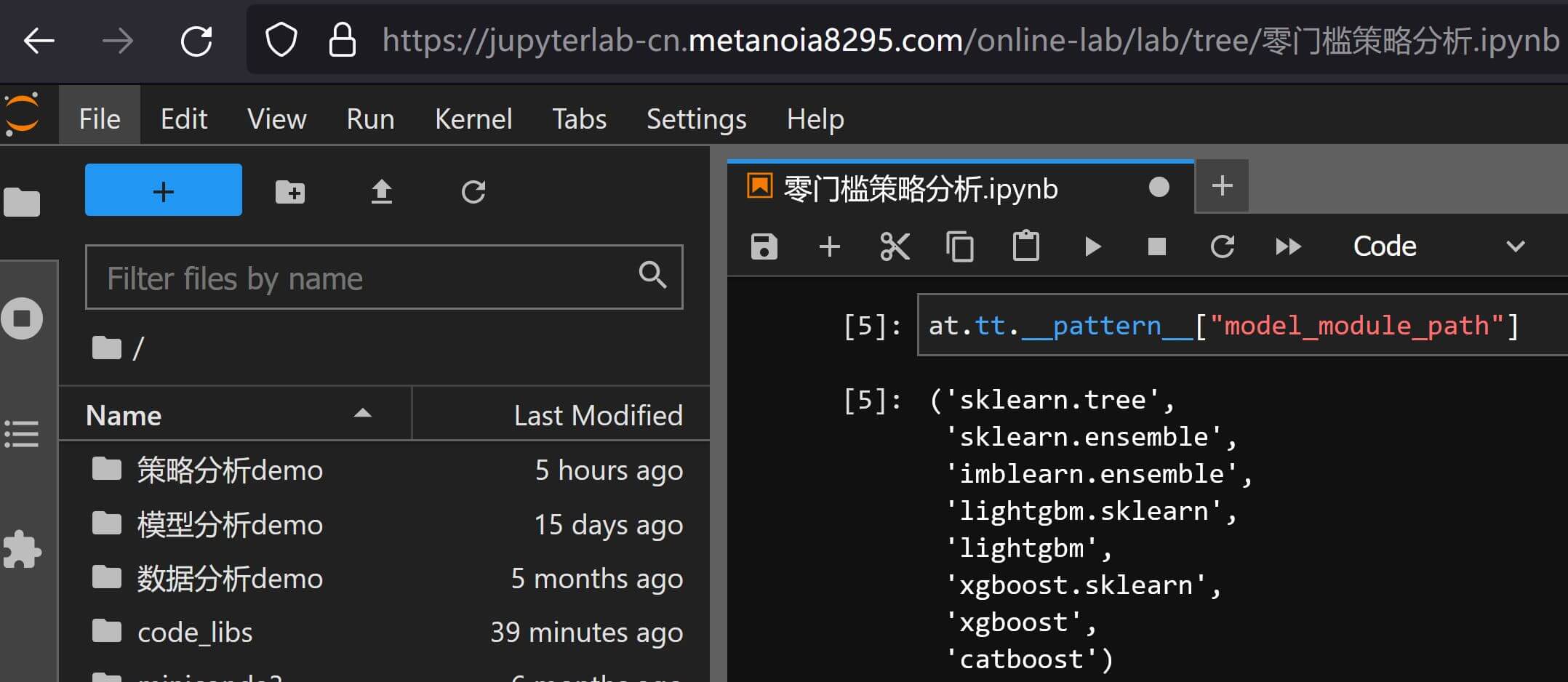
输出的报告示例可见1.4 案例展示,部分信息概述图如下: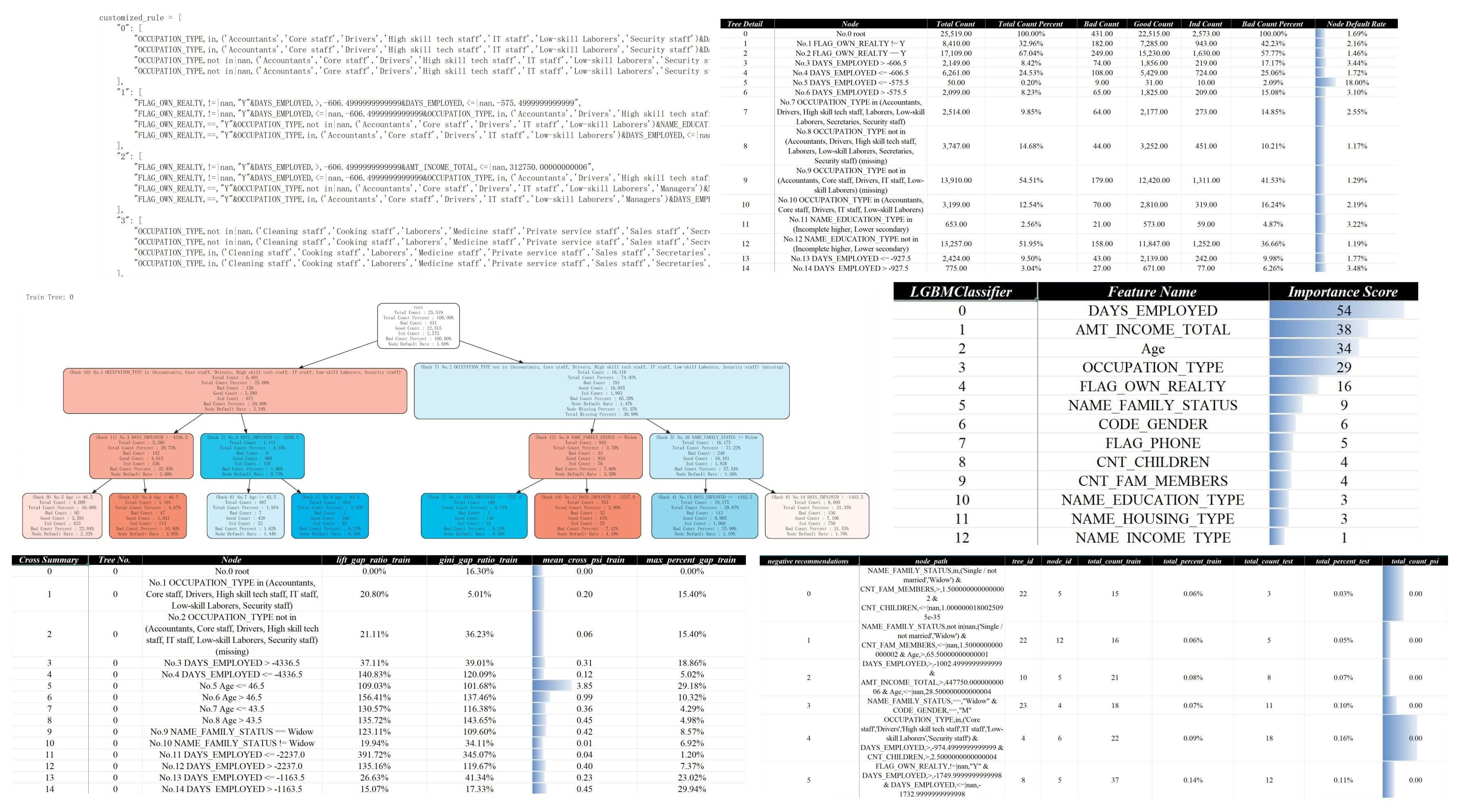
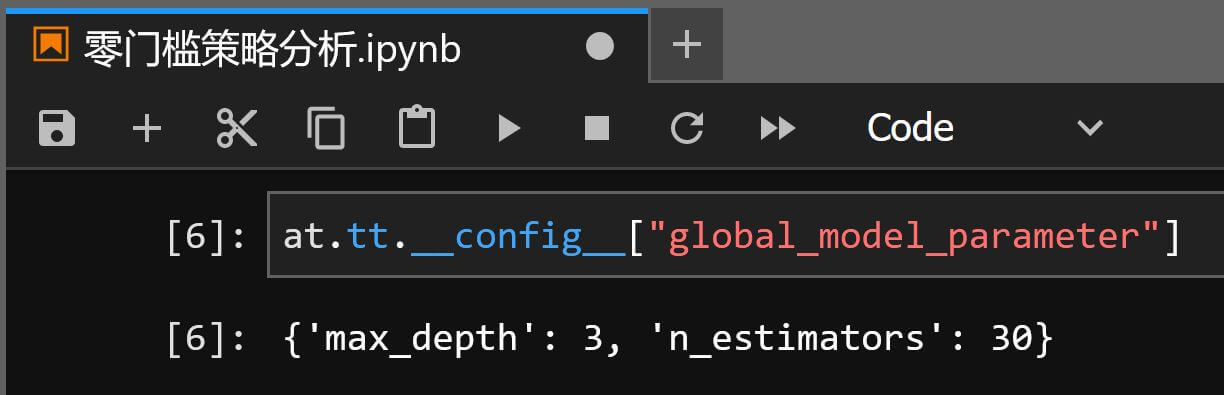
__config__["global_model_parameter"]中定义,通过3.1.3 自定义参数可覆盖2.2 数据预处理
此处数据预处理的参数与零基础实现高质量数据挖掘(模型分析篇)- 2.2 数据预处理中的完全一致:
模型的数据预处理一般来说会涉及缺失值处理和离散值处理,主要参数如下:
# 缺失值处理 # nan_mode 选填,默认None,可选min/max/mean/median # allow_nan 选填,默认False,是否允许有缺失值,自动调整 # 离散值处理 # allow_discrete 选填,默认False,是否允许有离散值,自动调整项 # one_hot_xgboost 选填,默认False,当模型为xgboost时,所有离散值OH处理 # one_hot_catboost 选填,默认False,当模型为catboost时,所有离散值OH处理 # max_discrete_num 选填,默认100,支持的离散类型变量的唯一值的上限的个数其他数据预处理方式
- 取值替换与极端值平滑处理:使用
data_flow的数据预处理部分,并搭配使用save_ori输出预处理后的结果,即可在model_flow或model_on_data中实现预处理- 数据提前分箱:使用
data_flow的数据分箱部分,并搭配使用save_woe_data输出预处理后的结果,即可在model_flow或model_on_data中实现预处理- 基于离散值与分箱的
One-Hot编码:和上一条相同,save_woe_data改成save_one_hot即可- 其他预处理:按需搜索,参考使用
pandas实现,或基于sklearn实现,网上教程极多,不一一举例常用的模型是带有自动推断的,比如常见的
lightgbm和xgboost等树模型,会在__pattern__中根据官方文档预设缺失和离散的处理能力:常用缺失离散预设值 自动推断示例
- 入参的
model_type_path会按全局预设的__pattern__["allow_nan"/"allow_discrete"]自动调整allow_discrete和allow_nan的取值- 建模数据选取时,会按
flow_data_type的可能取值:"WOE_"(默认值)和"ORI_",进行依次搜索,当入参的建模数据columns中没有"ORI_"/"WOE_"标识,会按数据自动搜索、自动分类离散值和数值型,并根据allow_discrete保留或删除离散值,根据allow_nan保留或填充缺失值- 虽然目前
sklearn的小部分模型开始支持缺失值和离散值入模,但大部分默认sklearn的模型都是不支持的,因此如果指定sklearn的模型,默认还是按不可缺失、不支持离散进行训练- 如果
model_type_path入参模型支持allow_nan或allow_discrete,但数据并没有缺失值或离散值,则会在数据检测完后,把allow_nan或allow_discrete调整为False,以避免后续需要allow_nan或allow_discrete调整为False才能允许的过滤器失效- 任何自动推断都不会对原始数据造成影响,会按模型适用范围建立子数据集来进行数据操作避免影响后续的其他操作
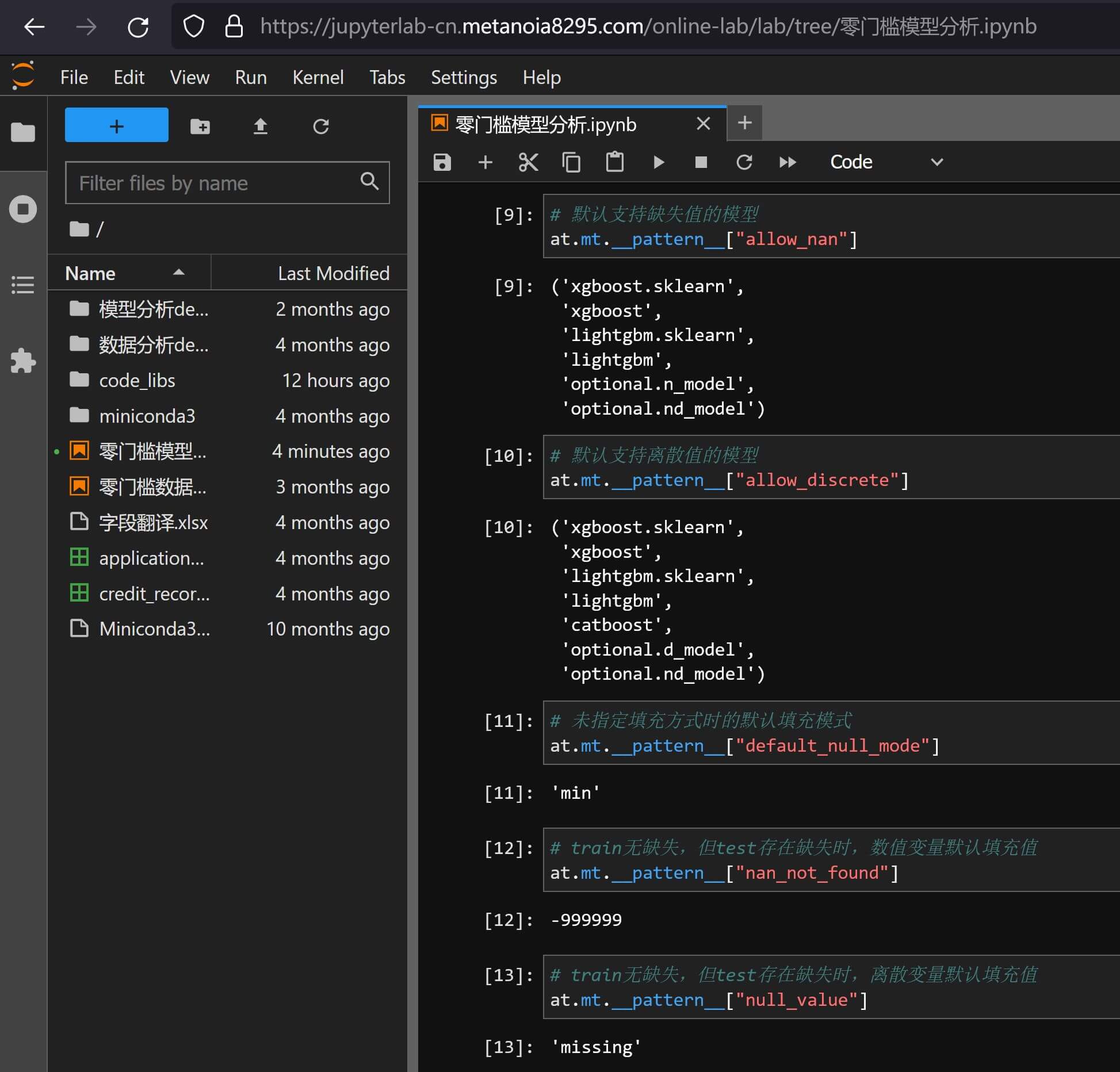
参数完全一样,以下几个默认值有变化:
# allow_nan 选填,默认True,是否允许有缺失值,自动调整
# allow_discrete 选填,默认True,是否允许有离散值,自动调整项
# one_hot_catboost 选填,默认True,当模型为catboost时,所有离散值OH处理其他细节略有差异,比如上会少一步自动推断示例中的4等,使用上的差异感知不强
2.3 标签定义
参考:零基础实现高质量数据挖掘(数据分析篇)- 2.3 标签定义
二分类任务最重要的一步就是定义目标变量,在分析时采用1和0来表示,一般来说,会使用
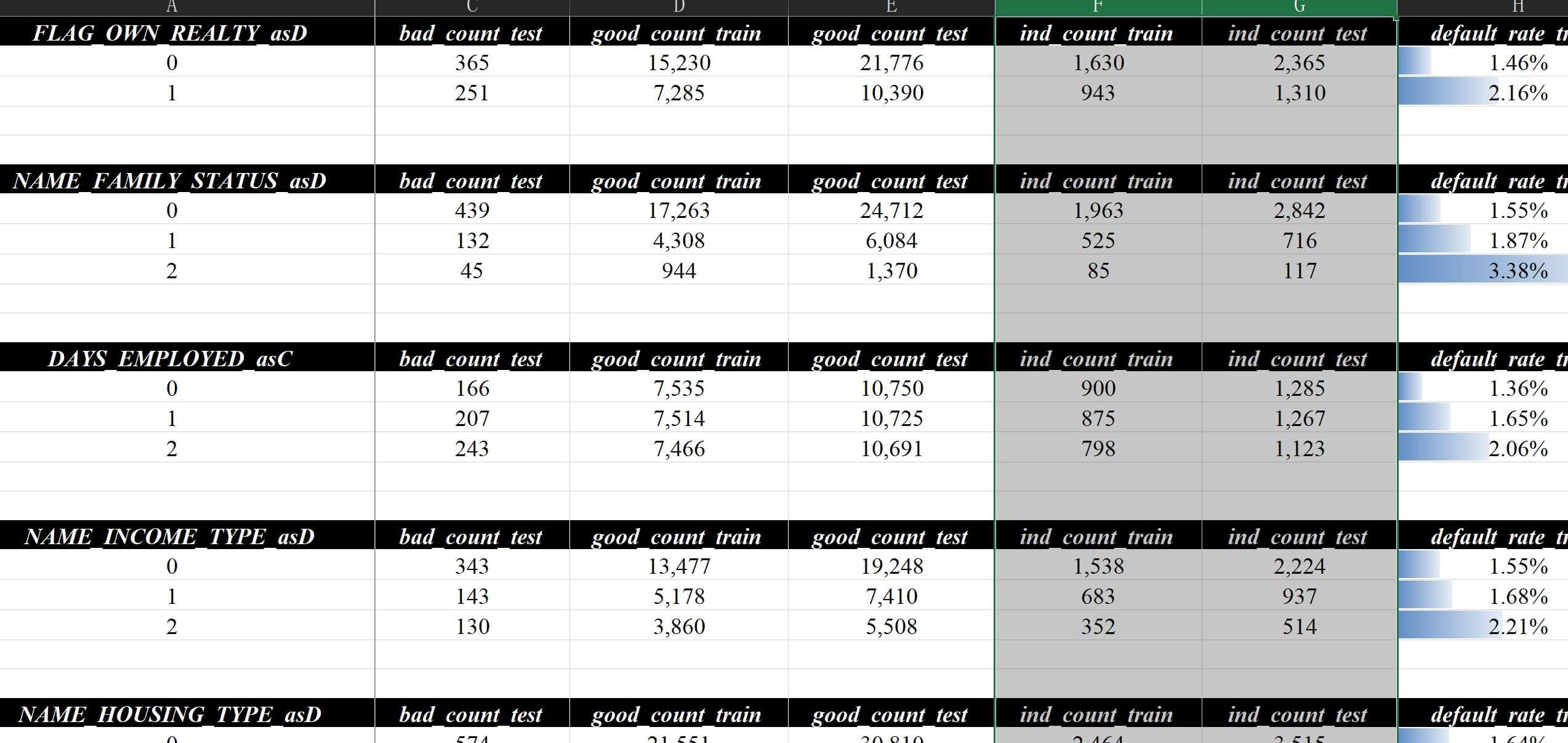
1代表有表现的数据(逾期客户、响应客户、目标客户等),使用0代表无表现的数据(正常客户、沉默客户等)# 基础定义 # ind 选填,默认2,响应中的不确定值 # bad 选填,默认1,响应中的negative # good 选填,默认0,响应中的positive # response 选填,默认为"target",数据的标签列中间状态的标记处理?不过如果大家项目做的多就会发现很多时候是需要有一个中间状态的体现的,比如:
- 逾期分析时按逾期天数计算滚动率发现,>=30天的逾期天数为目标客户(标记1)
- 和<=3天的逾期天数为正常客户(标记0)
- 那么(3, 30)之间的客户应该怎么处理呢?(标记?)
不合适的处理方式有些朋友说,我分析的时候把这些数据删了,不考虑不就行了?
直接删除数据其实是不建议的,因为如果你删除了这些特殊状态的客户,可能01分析的时候没有太大影响,但是是会影响到全量综合测算的(因为会影响分母大小),比如按01分析一条规则的测算命中率是3%,把2加进去的时候可能实际命中率就只有2.5%了,还没有正式投产测算就发生偏移是非常不专业的做法
还有些朋友说,我就不设置中间状态只保留01,把中间状态设成0或1,不就没这个问题了?
这种情况也是不建议的,01的定义是会直接影响到后续有效性和稳定性的,不恰当的01设置可能会导致分析的目标紊乱出现分析偏差(如:分箱切分点阈值偏移),况且谁也不能保证永远没有特殊状态的存在(比如我把未激活的客户当作2来评估分布)
合适的处理方式所以我设计的模块虽然针对二分类,但标签定义默认是能包含012三种状态的,2可以配合各种不同状态(未激活、沉默、被拒绝、营销未响应等)中间状态的数据集进行测算和展示,如下:
中间状态客户示例 中间状态仅做展示并不影响使用01的进行核心测算和分析
模板太单一?可能还有朋友抬杠说我不做风险逾期分析你这个报告的模板不适合我,太单一了只有ind/good/bad
自定义报告输出这个模板其实也可以改的,主要通过修改全局模板,简单配置如下:
修改目标变量展示名称 这样所有对应的bad/good/ind等名称都会发生改变,如下图所示:
报告示例(修改目标变量名称) 具体可以下载文件查看:
数据分析报告vx.xlsx,参数调整范围也可查看6.1 报告格式调整
策略工具也必须是二分类,因此不支持回归任务
2.4 数据切片
参考:零基础实现高质量数据挖掘(数据分析篇)- 2.4 数据切片
数据切片是可选的参数,但因为实在是太基础了,所以提前说一下,细心的朋友可能会发现上面展示的报告内容里面有好多
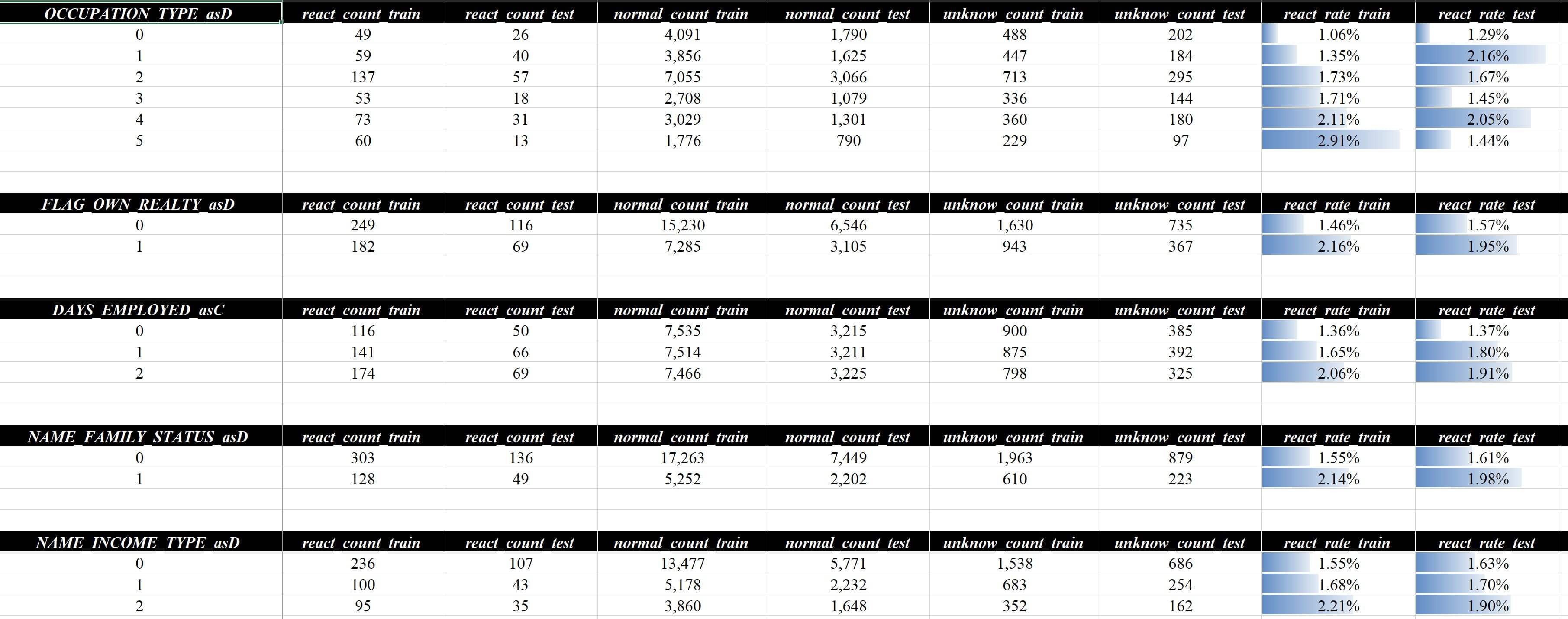
Random1/2/3是怎么回事?比如这一页:
切片示例(部分) 上面报告当中的
Random1/2/3其实是代码生成的数据切片的一种,上图的具体含义是在计算相关性时,除了按整体数据量计算,还把数据集分为Random1/2/3三片,每片数据分别计算相关性,最后汇总展示,那么来看一下数据切片设定的参数定义:
# 数据切片相关 # split_col_name 选填,默认None,可选时间序列或离散值,用来对数据进行分割 # is_time_series 选填,默认True,当输入非响应列时,按时间序列预先分割处理 # use_train_time 选填,默认False,处理时间时,使用开发时间区间来映射全局 # max_split_part 选填,默认10,支持的数据切片的上限,过大会导致性能问题 # format_time_edge 选填,默认False,当处理时间时,时间区间两端展示为无穷 # stratified_split 选填,默认False,等量分割数据抽样时,是否使用分层抽样 # split_data_method 选填,默认3,可选"M"/"2W-SUN",int时使用等量分割 # split_random_state 选填,默认None,数据在按时间划分抽样时的随机种子 # use_response_split 选填,默认True,当split未指定时采用response
切片的信息会体现在树模型结构的详情展示上,比如策略分析报告v1-lgb.xlsx中的模型评估 - 节点详情页面: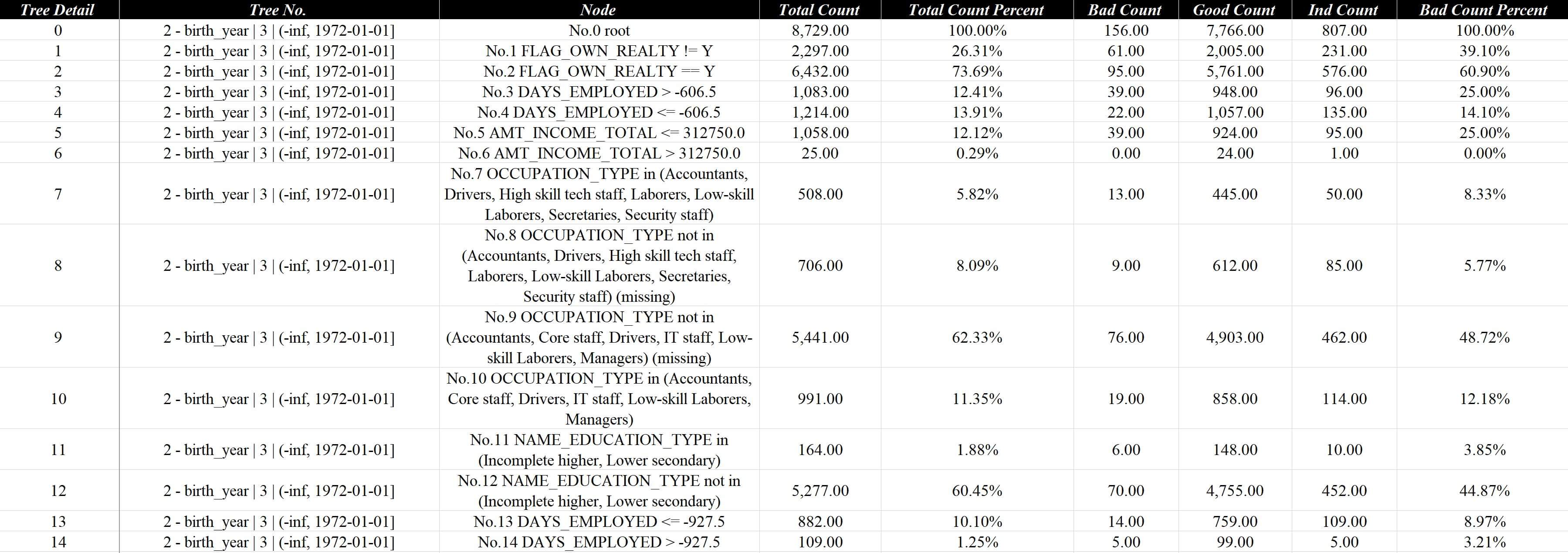
还可以用在排序和分布的稳定性对比上,比如页面模型评估 - 排序稳定性和模型评估 - 分布稳定性等页面: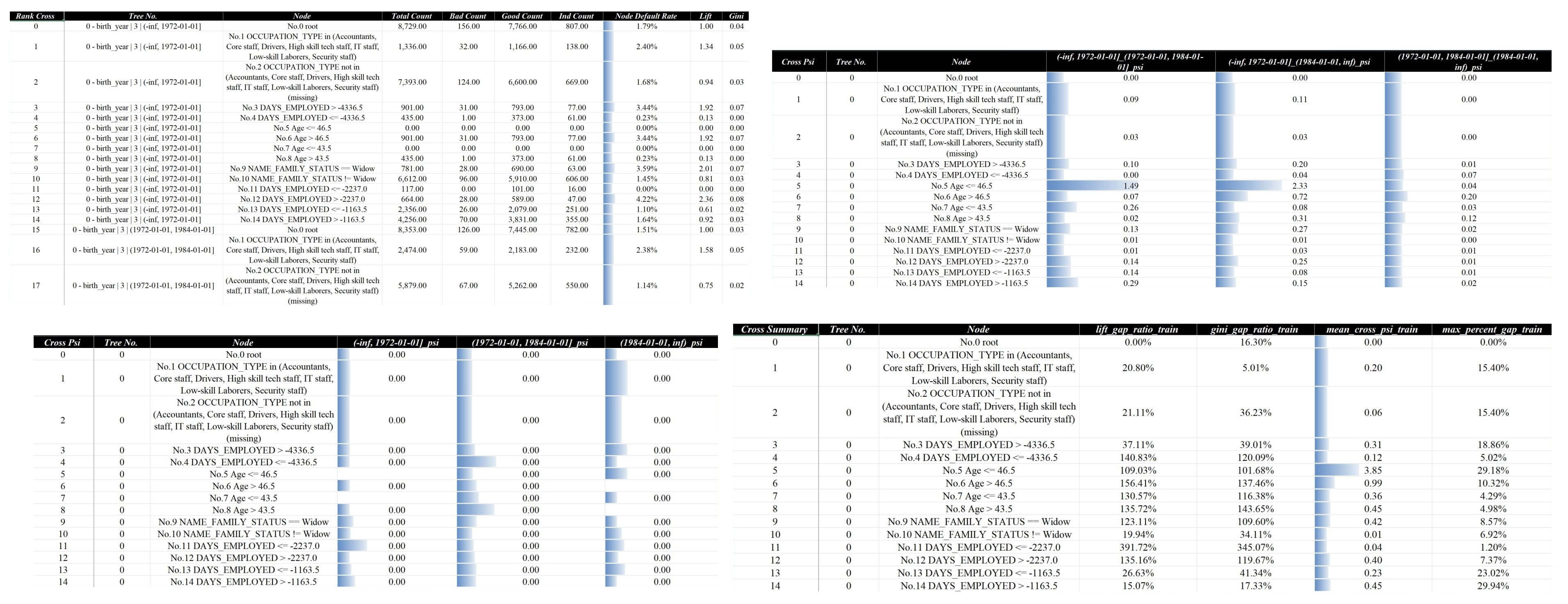
2.5 多数据映射
参考:零基础实现高质量数据挖掘(数据分析篇)- 2.5 多数据映射
上述
test_data的定义为None或dataframe,实战中会面临多个数据集的测算需求,如:验证、测试、样本外、全量等不同维度,考虑到这些需求,实际上test_data是支持list入参的,参数如下:# alpha_tools.Analysis参数 # train_name 选填,默认None,train_data的名称,入参str并和test_names联动 # test_names 选填,默认None,test_data(s)的名称,入参str/list并和test_data(s)联动 # auto_dir_cn 选填,默认True,根据train_name和test_names自动修改train_test_dir_cn值只是
test_data为list时,需要同时指定train_name和test_names,不然会报错,参考用例如下:at.Analysis.data_flow( df_train, "./数据分析demo/v2-more/v2-more.xlsx", # 同时入参两个数据集:测试、全量 test_data=[df_test, df_data], train_name="开发", test_names=["测试", "全量"], response="target", split_col_name="birth_year", use_train_time=True, )多数据映射 可一次性得到多个数据集的分析结果报告,并会基于
output_name自动添加后缀名,如上图展示的数据分析报告v2-more-开发-测试.xlsx和数据分析报告v2-more-开发-测试2.xlsx,具体实现上其实是通过配置文件还原的方式来操作,后面章节6.3 配置映射和还原会展开描述,至于多份文件如何合并与浏览?也会在后面章节6.5 报告合并与数据合并中具体展开描述
涉及参数与data_flow完全一致,使用时对应入参修改为tree_flow即可,样例代码为:
at.Analysis.tree_flow(
df_train, "./策略分析demo/v1-lgb-more/v1-lgb-more.xlsx",
# df_train, "./策略分析demo/v1-lgb/v1-lgb.xlsx", test_data=df_test,
# 同时入参两个数据集:测试、全量
test_data=[df_test, df_data], train_name="开发", test_names=["测试", "全量"],
# 目标定义 & 切片定义
response="target", split_col_name="birth_year", use_train_time=True,
exclude_column=["ID", "DAYS_BIRTH"], # 多变量分析时,DAYS_BIRTH会干扰Age的分析
add_info="ID", # 主键添加
)
获取的样例文件可见:
和前文类似,配置还原与报告合并请见:4.3 配置映射和还原、4.5 报告合并与数据合并
2.6 权重调整
参考:零基础实现高质量数据挖掘(模型分析篇)- 2.6 权重调整
入参与
data_flow是一样的,还是通过sample_weight_name参数实现,只是这个模块是通过将sample_weight_name的入参传递给模型fit函数中的sample_weight参数来间接实现,如果
model_flow底层调用的建模依赖模块不支持权重调整,则传递的参数在model_flow环节无效,不过也要综合来看,比如默认的statsmodels.api.Logit建模类的fit函数并没有sample_weight参数,但如果是data_flow已经入参sample_weight_name调整过woe数据权重了,相当于已经间接实现了权重调整的目的了,statsmodels.api.Logit本身并不能在建模环节支持权重调整也没有太大的影响,另外关于
class_weight没有单独实现,感觉单独实现有些冗余,有需求的请按需要的class_weight自行添加sample_weight_name并指定入参
2.7 数据翻译
参考:零基础实现高质量数据挖掘(数据分析篇)- 2.7 数据项翻译
一般来说直接使用原始数据分析即可,也可以直接修改原始
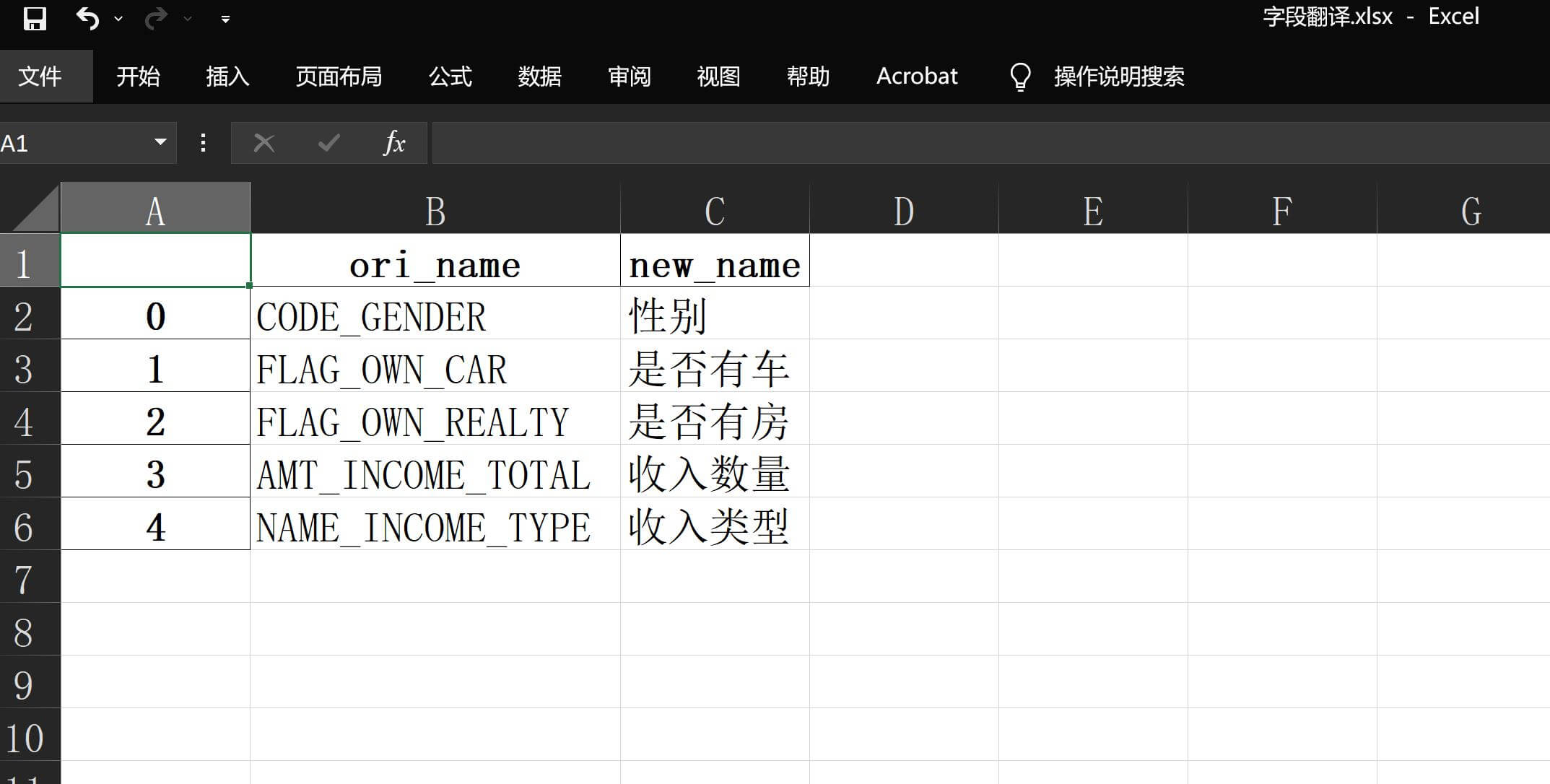
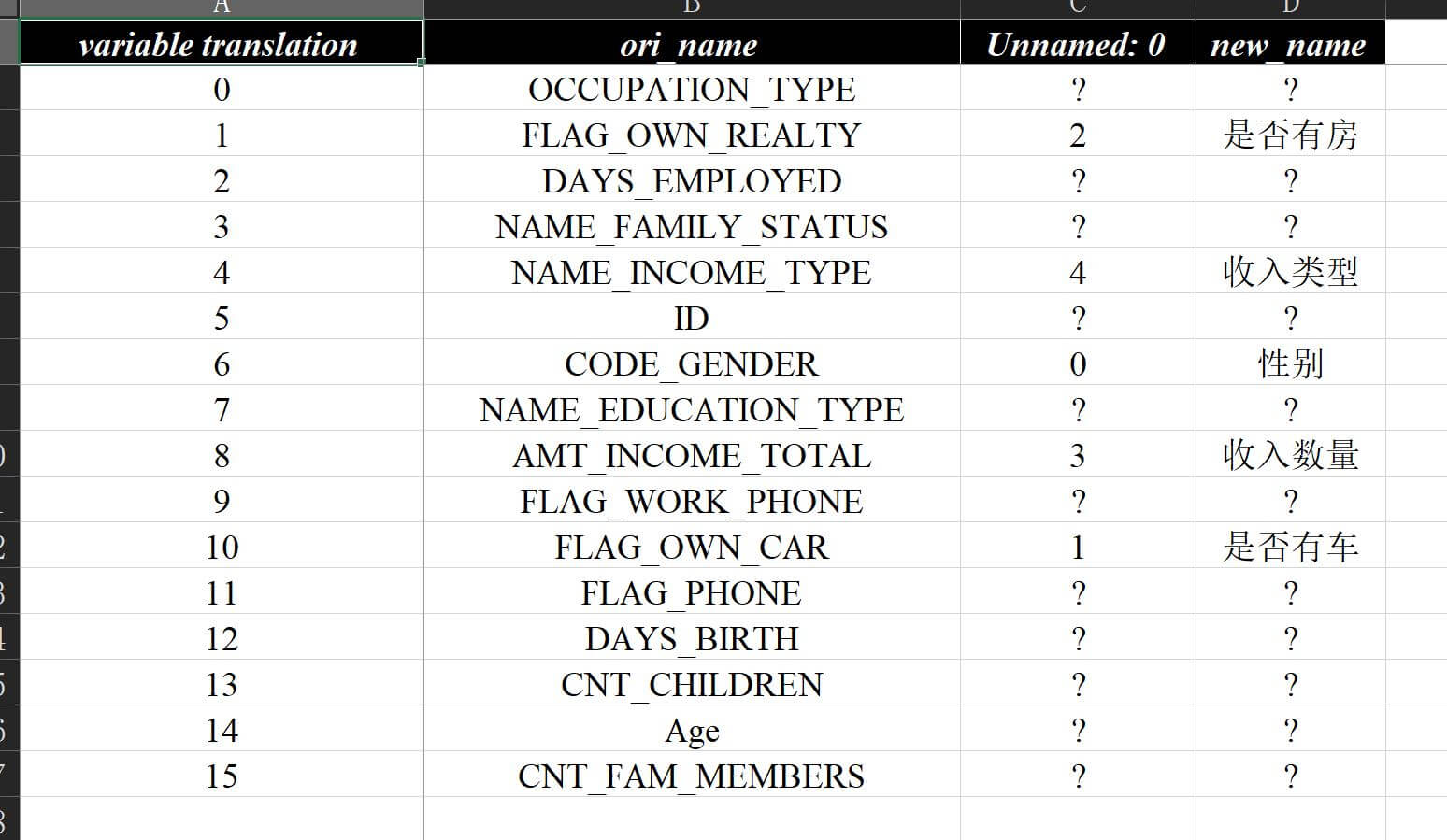
dataframe.columns来调整报告内容,不过总有一些情况要求既保留原始数据内容,又体现内容转换,因此做了这个翻译方面的定义,具体内容如下:# 数据翻译 # var_dict_path 选填,默认None,变量翻译的字典路径 # var_series_name 选填,默认"var_name",变量文件字典中待翻译变量的列名称 # var_explain_name 选填,默认"var_explain",变量文件字典中变量解释的列名称举例来说,假如我自定义了一份
字段翻译.xlsx并放在同一路径下,里面包含的内容如下:数据翻译 在使用的时候直接指定参数即可:
at.Analysis.data_flow( df_train, "./数据分析demo/v2-rename/v2-rename.xlsx", test_data=df_test, response="target", split_col_name="birth_year", var_dict_path="./字段翻译.xlsx", var_series_name="ori_name", var_explain_name="new_name" )可在输出结果
数据分析报告v2-rename.xlsx相应的位置看到已经完成了翻译标注:数据翻译1 数据翻译2 其中
变量评估 - 翻译页会把字段翻译.xlsx中匹配到的行的所有列全部粘贴保留
2.8 高性能实现
参考:零基础实现高质量数据挖掘(数据分析篇)- 2.8 高性能实现
除了底层混用
python/c/c++实现高性能计算函数,在变量分析的流程是默认开启并发的,能同时平行加速处理多个变量缩短整体分析时间,涉及的参数如下:# 并发相关 # multi_num 选填,默认8,多进程或多线程的并发数 # chunk_size 选填,默认1,多进程时每个进程包含的并发数 # enable_lock 选填,默认True,并发锁,可间接调整并发运行状况 # enable_multi 选填,默认True,是否启用多进程或多线程加速计算参数比较简单不再展开描述,其他实践中的一些简单备注事项如下:
备注事项
同时参考:零基础实现高质量数据挖掘(模型分析篇)- 2.8 高性能实现
参数是完全一样的,混合编程的实践也是完全一样的,只是模型分析的并发多通过模型本身参数
n_jobs来间接实现,而其他如相关性筛选等功能的并发,因为底层的numpy并发性能已经很好了,因此也多是多线程实现,不太会有data_flow面临的multiprocessing多进程的问题
3.策略搜索和评估
这一部分介绍策略的生成、搜索评估和策略相关的一些分析,有助于理解本模块核心部分的整体运作机制,在必要时能更好的结合业务场景提炼针对性更强的策略规则
3.1 自定义建模
这一节与零基础实现高质量数据挖掘(模型分析篇)- 4.2 自定义建模有一定的相似性,自定义建模涉及的主要参数有:
# 模型定义
# model_exists 选填,默认None,可入参已训练模型的pkl路径
# customized_variables 选填,默认[],设定变量列表来定制建模,入参后跳过变量筛选步骤
# customized_parameter 选填,默认{},建模时的入参,会覆盖global_model_parameter重复项除此之外,把数据过滤和筛选合并到了此章节
3.1.1 数据过滤和筛选
在tree_tools函数中,不再具备复杂的建模前数据过滤的机制,如果有这方面的需求,推荐使用零基础实现高质量数据挖掘(数据分析篇)- 4 数据过滤和筛选,或零基础实现高质量数据挖掘(模型分析篇)- 3 数据过滤和筛选前置筛选数据,并基于3.1.4 继承已有模型策略化已训练的模型,此处主要提供基于树模型的筛选方式,参数为:
# 变量筛选
# limit_var_num 选填,默认30,按重要性筛选保留最终模型变量数
# zero_imp_filter 选填,默认True,变量筛选后,自动排除重要性为零的变量参数说明可类比参考:零基础实现高质量数据挖掘(模型分析篇)- 3.3 重要性筛选、零基础实现高质量数据挖掘(模型分析篇)- 3.6 变量数量限制,差异在于筛选时所使用的模型和参数都与主模型定义的一致,不再单独定义
3.1.2 自定义变量
参考:零基础实现高质量数据挖掘(模型分析篇)- 4.2.1 自定义变量
有些建模场景可能需要锁定入参变量,此时可以通过
customized_variables入参实现,此时不会再进行筛选和搜索(当然exclude_column还是会生效的),会直接使用customized_variables中的变量建模,比如我希望比较离散值数据在one-hot前后用lightgbm建模,模型表现是否会存在差异,案例如下,首先
customized_variables入参实现lightgbm基于离散值原始值建模,代码如下:discrete_cols = df_train.dtypes[df_train.dtypes == object].index.tolist() at.Analysis.model_flow( df_train, "./模型分析demo/v6-lgb/v6-lgb.xlsx", test_data=df_test, # 目标定义 & 切片定义 response="target", split_col_name="birth_year", use_train_time=True, exclude_column=["ID", "weight"], # 排除权重和离散值 add_info="ID", # 主键添加 # 指定使用训练的class并不进行打分转化 model_type_path="lightgbm.sklearn.LGBMClassifier", convert_score=False, customized_variables=discrete_cols, )自定义变量建模示例
用法上也一致,也可以单独做一个离散值变量的策略集,样例如下:
discrete_cols = df_train.dtypes[df_train.dtypes == object].index.tolist()
at.Analysis.tree_flow(
df_train, "./策略分析demo/v2-lgb/v2-lgb.xlsx", test_data=df_test,
# 目标定义 & 切片定义
response="target", split_col_name="birth_year", use_train_time=True,
exclude_column=["ID", "DAYS_BIRTH"], # 多变量分析时,DAYS_BIRTH会干扰Age的分析
add_info="ID", # 主键添加
customized_variables=discrete_cols,
)
结果可见策略分析报告:策略分析报告v2-lgb.xlsx,在排除数值变量后,性别、资产状况等元素被选了出来,差异点非常有意思
3.1.3 自定义参数
参考:零基础实现高质量数据挖掘(模型分析篇)- 4.2.2 自定义参数
除自定义模型外,还可以通过
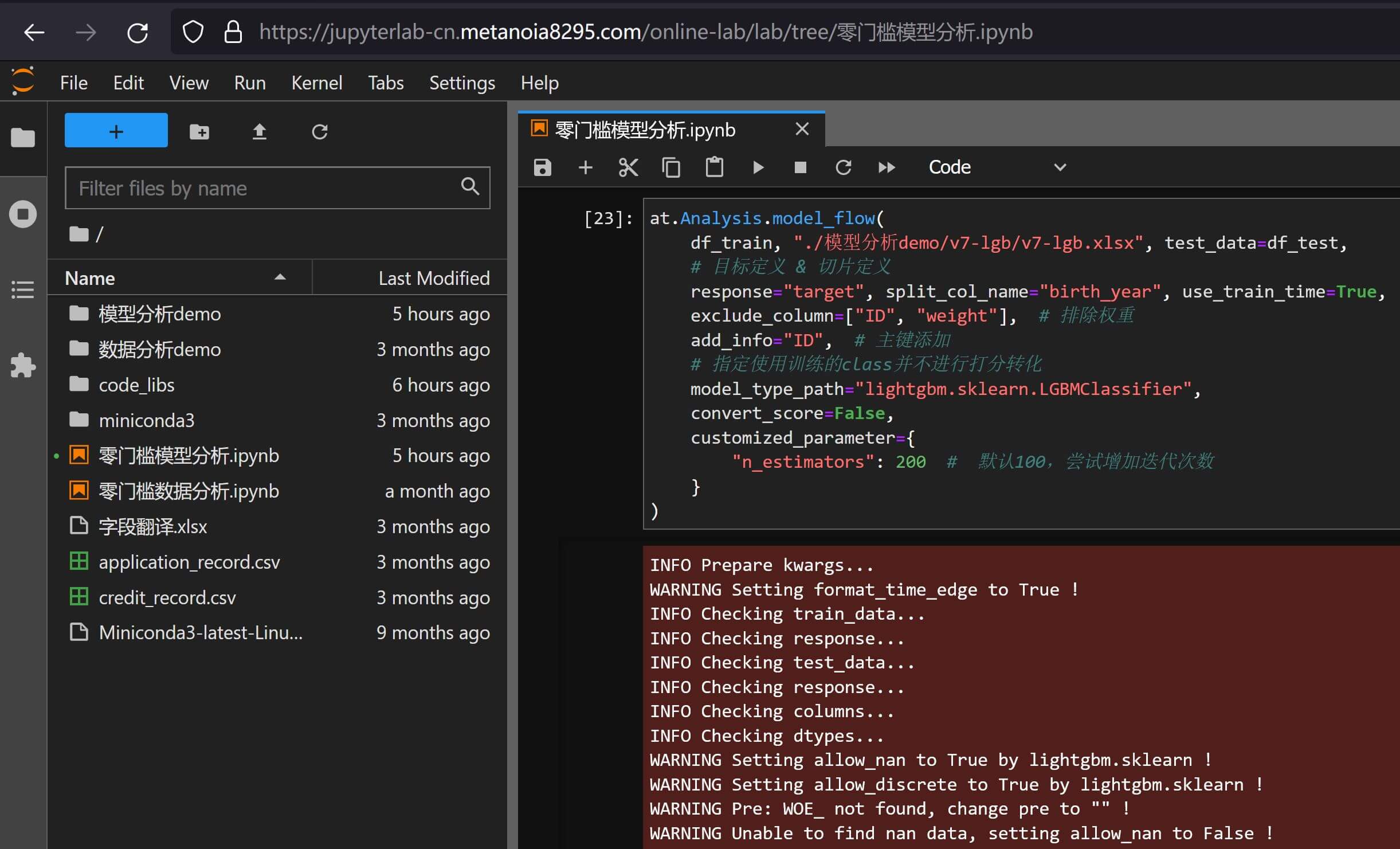
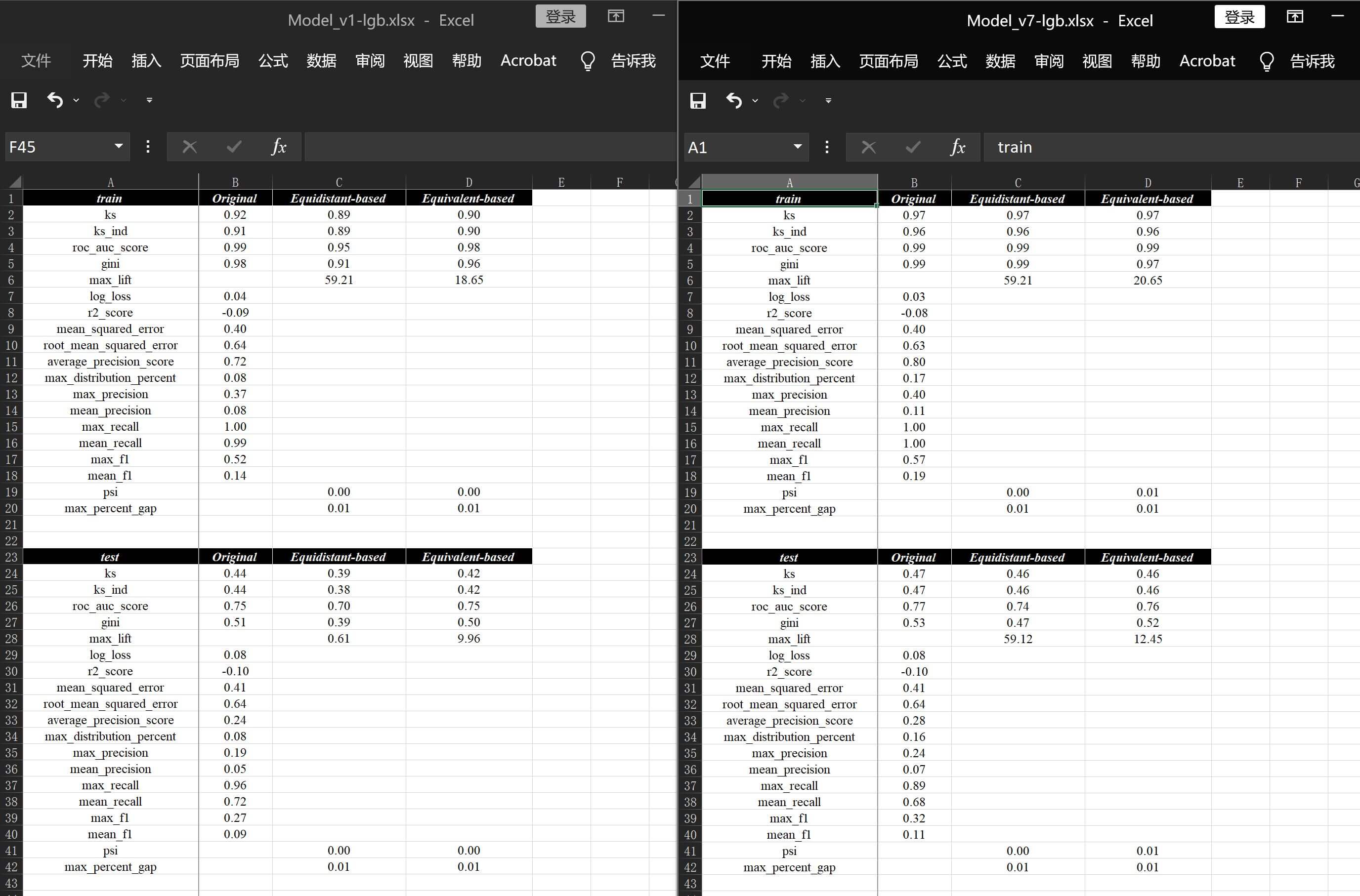
customized_parameter来自定义建模入参,在这之前的lightgbm训练案例使用的都是模型默认预置的参数,这里我们尝试按官方文档入参看一下结果会有什么不同:at.Analysis.model_flow( df_train, "./模型分析demo/v7-lgb/v7-lgb.xlsx", test_data=df_test, # 目标定义 & 切片定义 response="target", split_col_name="birth_year", use_train_time=True, exclude_column=["ID", "weight"], # 排除权重 add_info="ID", # 主键添加 # 指定使用训练的class并不进行打分转化 model_type_path="lightgbm.sklearn.LGBMClassifier", convert_score=False, customized_parameter={ "n_estimators": 200 # 默认100,尝试增加迭代次数 } )自定义参数建模示例 从模型报告
模型分析报告v7-lgb.xlsx来看,结论基本上是大力出奇迹:lightgbm增大n_estimators后对比翻倍迭代次数,虽然对稳定性没什么帮助,但性能上确实会比默认要好上一点点。。。
另外,参数
customized_parameter入参list时会自动进行模型参数搜索,超参数搜索坑也很大,可通过查阅4.4 模型参数搜索来了解我在解决方案上的架构设计
使用方式上基本一致,只是不具备超参数搜索功能,有这方面需求请先基于零基础实现高质量数据挖掘(模型分析篇)- 4.4 模型参数搜索完成树模型的训练,再基于3.1.4 继承已有模型策略化已训练的模型,
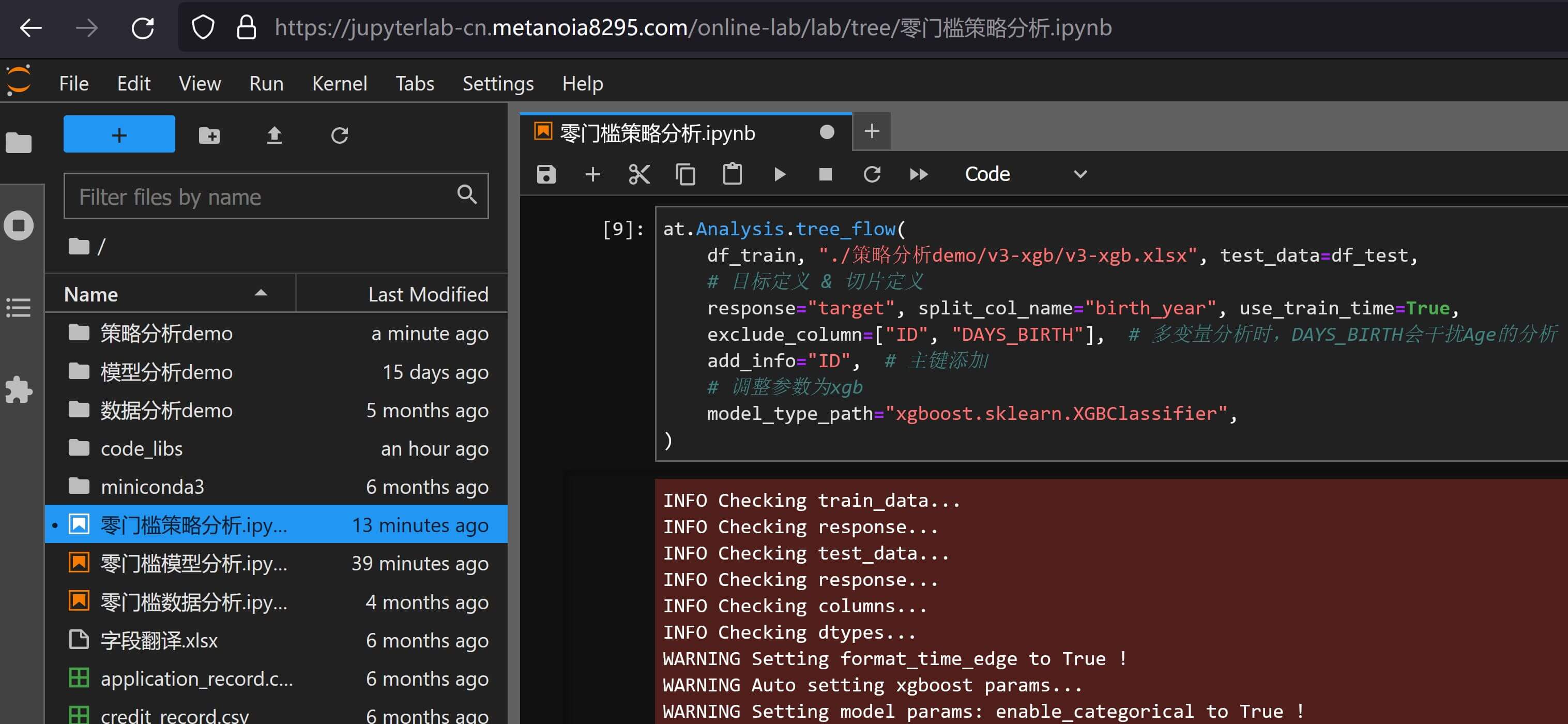
考虑到xgboost刚支持离散值不久,首先来比较一下xgboost和lightgbm策略化以后的差异,使用xgboost的样例代码如下:
at.Analysis.tree_flow(
df_train, "./策略分析demo/v3-xgb/v3-xgb.xlsx", test_data=df_test,
# 目标定义 & 切片定义
response="target", split_col_name="birth_year", use_train_time=True,
exclude_column=["ID", "DAYS_BIRTH"], # 多变量分析时,DAYS_BIRTH会干扰Age的分析
add_info="ID", # 主键添加
# 调整参数为xgb
model_type_path="xgboost.sklearn.XGBClassifier",
)
xgboost模型策略化样例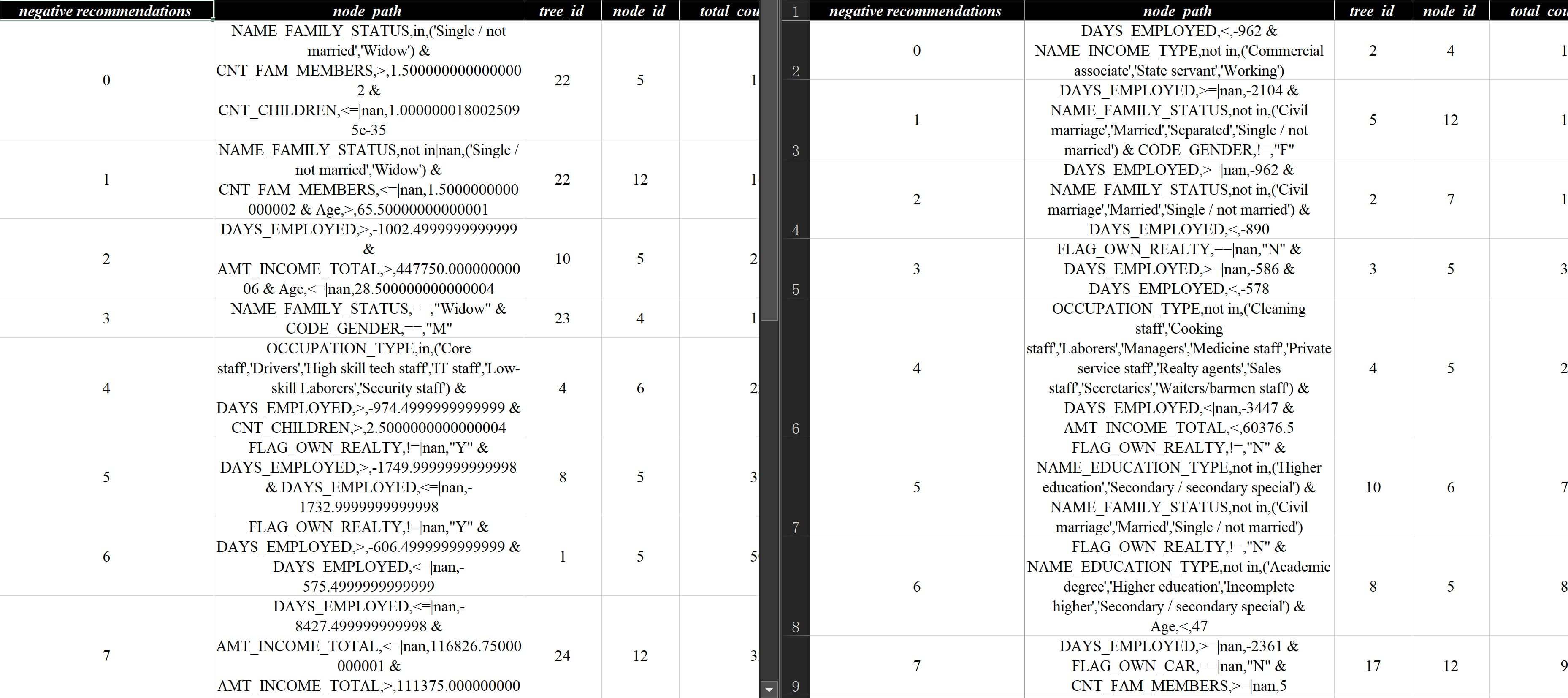
lightgbm和xgboost负向规则对比参考从结果报告策略分析报告v3-xgb.xlsx来看,推荐的负向策略靠前几条更多的集中在了工作时长、工作类型上,当然因为没有限制节点数量,单规则命中的数量还是比较少的,
- xgboost:https://xgboost.readthedocs.io/en/stable/python/python_api.html#module-xgboost.sklearn
- lightgbm:https://lightgbm.readthedocs.io/en/latest/pythonapi/lightgbm.LGBMClassifier.html
- sklearn.ensemble:https://scikit-learn.org/stable/modules/classes.html#module-sklearn.ensemble
- sklearn.tree:https://scikit-learn.org/stable/modules/generated/sklearn.tree.DecisionTreeClassifier.html
- catboost:https://catboost.ai/en/docs/concepts/python-reference_catboostclassifier
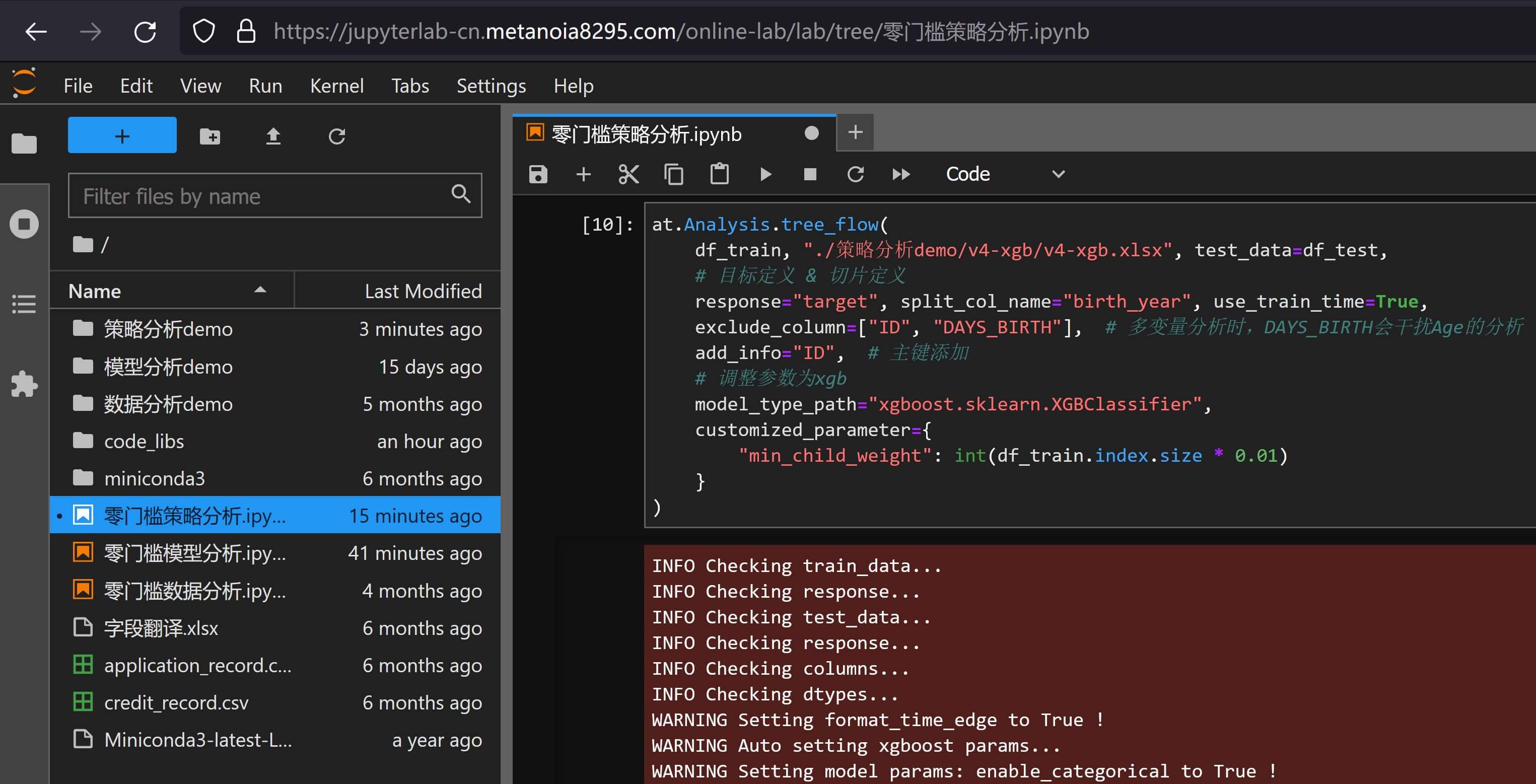
那现在假设我们需要限制每条规则最少命中1%的总客户数,那根据xgboost的文档的内容,可以通过输入参数min_child_weight到customized_parameter来指定,样例如下:
at.Analysis.tree_flow(
df_train, "./策略分析demo/v4-xgb/v4-xgb.xlsx", test_data=df_test,
# 目标定义 & 切片定义
response="target", split_col_name="birth_year", use_train_time=True,
exclude_column=["ID", "DAYS_BIRTH"], # 多变量分析时,DAYS_BIRTH会干扰Age的分析
add_info="ID", # 主键添加
# 调整参数为xgb
model_type_path="xgboost.sklearn.XGBClassifier",
customized_parameter={
"min_child_weight": int(df_train.index.size * 0.01)
}
)
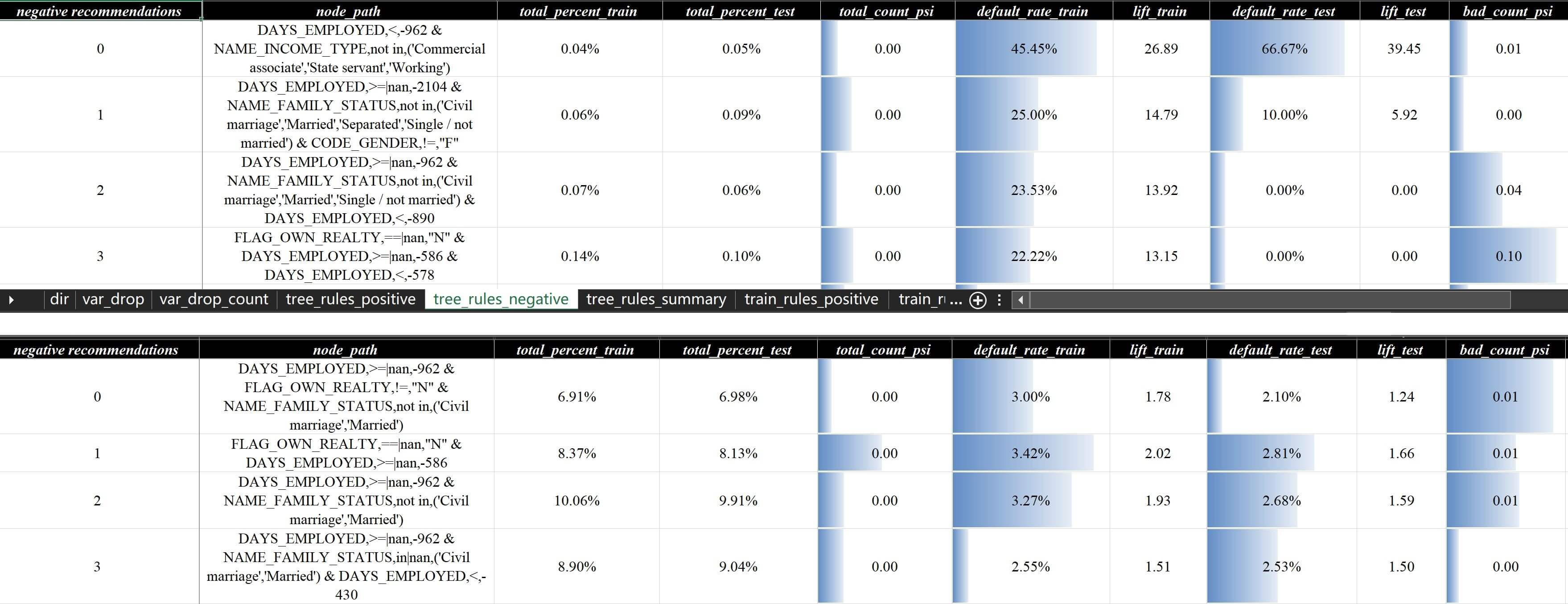
xgboost调整min_child_weight样例和之前的报告对比,新的报告策略分析报告v4-xgb.xlsx推荐的负向规则成功实现了单规则命中占比的大幅提升,当然代价是命中的群里的精准度会有一定的滑坡,觉得占比偏高可以调低参数继续尝试,但如果要实现较大群体的较强排序能力,一般来说还是上模型会更综合、稳妥一点,或者需要多参数反复尝试,另外限制规则占比还可以通过3.2.2.1 基于有效性搜索中的limit_rule_percent参数来实现,原理上有一定的差异,
与之类似,模型其他参数的调整也是通过入参customized_parameter来实现,比如同一个模型切换算法、进行随机抽样或单调约束等,定义的参数会直接穿透到底层的代码中,具备了足够的灵活性
3.1.4 继承已有模型
如之前所述,本模块的建模和数据过滤都较为基本,如果希望使用零基础实现高质量数据挖掘(模型分析篇)- 4.4 模型参数搜索或零基础实现高质量数据挖掘(模型分析篇)- 3 数据过滤和筛选等模型特性,可以使用model_exists参数继承已训练的模型,
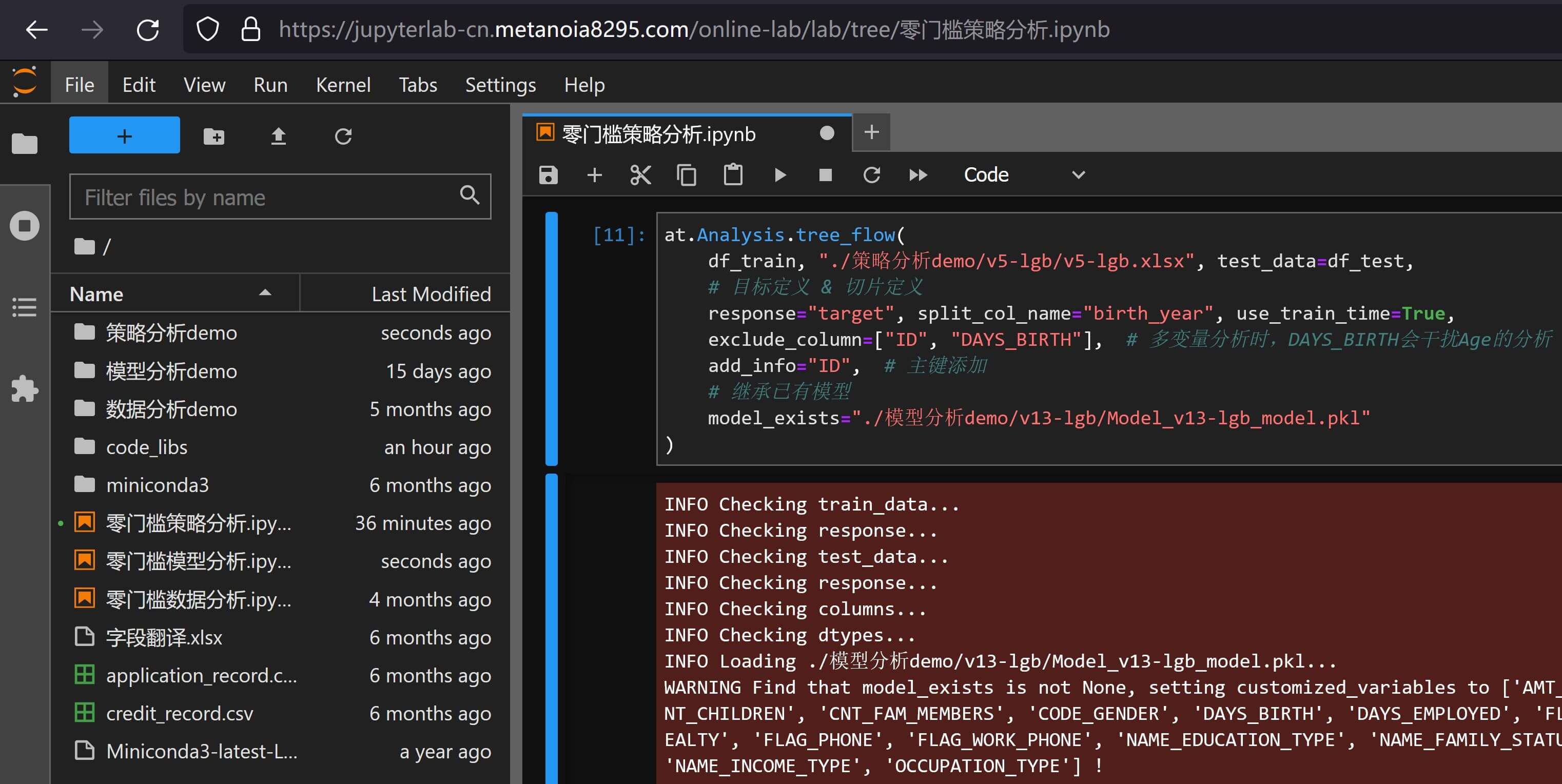
比如假设我的模型来自零基础实现高质量数据挖掘(模型分析篇)- 4.4.4 随机搜索,在这里跳过训练直接展开的代码样例如下:
at.Analysis.tree_flow(
df_train, "./策略分析demo/v5-lgb/v5-lgb.xlsx", test_data=df_test,
# 目标定义 & 切片定义
response="target", split_col_name="birth_year", use_train_time=True,
exclude_column=["ID", "DAYS_BIRTH"], # 多变量分析时,DAYS_BIRTH会干扰Age的分析
add_info="ID", # 主键添加
# 继承已有模型
model_exists="./模型分析demo/v13-lgb/Model_v13-lgb_model.pkl"
)
这样就可以展开已有的模型,间接实现在tree_tools中融合model_tools的一系列特性,可见策略分析报告v5-lgb.xlsx,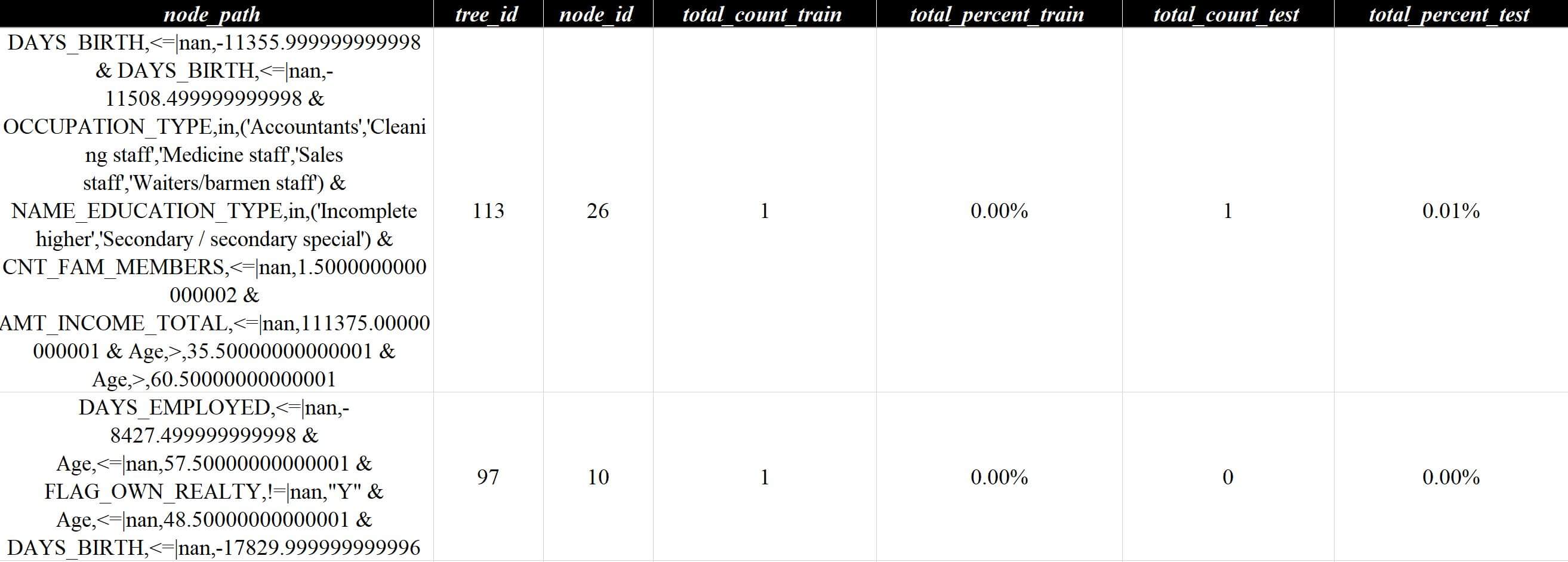
lightgbm预训练模型规则展开案例
这个案例里面的模型深度很深、节点很细,足足有148颗树展开,策略报告文件巨大,抽象出来的规则很多数量都只命中1,这就是模型层面过拟合的宏观现象在策略维度上微观具象化的体现
- 因2.2 数据预处理中提到的可解释性问题,当使用
model_flow函数训练catboost中的模型时,需要入参one_hot_catboost为False,获取到的模型结果才能被tree_flow函数继承展开 - 另外
model_flow中task_type为regression的模型也是不支持直接继承展开的,只能展开task_type为binary的模型 - 如果需要展开
model_on_data的模型,则需要手动把model_on_data输出的数据入参给tree_flow - 如果在
tree_flow的model_type_path入参了回归模型,理论上底层构建规则和解析规则一致时是不会报错的,但解析完以后也是按分类模型的流程来出报告的,因此推荐正常使用分类模型,比如xgboost则推荐使用xgboost.sklearn.XGBClassifier而不是xgboost.sklearn.XGBRegressor
3.2 自定义策略
本节介绍如何实现策略自定义,包括基于建模的自动策略化以及基于专家经验的手动策略化
3.2.1 手动定义规则
手动输入规则涉及到的参数主要有两个:
# 自定义规则
# customized_rule 选填,默认None,可手动自定义树结构的list或dict
# customized_nodes_dict 选填,默认{},通过或拒绝的树和节点customized_rule用来定义树结构,customized_nodes_dict用来选择特定的规则节点,
- 规则主体采用变量名称+判定条件+判定内容的格式来表达,其中用
,进行连接,比如col1,>=,2,这三个元素前后允许多余的空格,比如col1 , >= , 2,但内部不允许多余的空格,因为变量名称支持包含空格,且判定内容为离散值时也支持包含空格 - 如果需要包含缺失值
np.NaN可以在判定条件部分添加|nan来表达,比如col1,>=|nan,2,当规则有|nan但数据没有np.NaN绘图时会隐去|nan - 如果存在多个逻辑依次生效,则用
&依次连接多个表达式,比如col1,>=,2 & col2,<,10,从左到右定义顺序即为从浅到深 - 入参为
list时,多条规则需要构建成一颗完整的树,比如["col1,>=,2", "col1,<|nan,2"],只输入一条规则时,会按树结构补全其他规则,此时按"0"做为key补全树名称 - 入参为
dict时,支持有交集的不同规则入参,通过不同的key区分即可,value取值为上述的list规则集,比如{"0": ["col1,>=,2"]; "1": ["col1,>=,3"]}
参数customized_rule用例如下,不使用customized_nodes_dict也是可以的,此时按3.2.1 自动策略搜索进行正负规则选择:
at.Analysis.tree_flow(
df_train, "./策略分析demo/v6/v6.xlsx", test_data=df_test,
# 目标定义 & 切片定义
response="target",
split_col_name="birth_year", use_train_time=True,
exclude_column=["ID", "DAYS_BIRTH"], # 多变量分析时,DAYS_BIRTH会干扰Age的分析
add_info="ID", # 主键添加
customized_rule=[
"DAYS_EMPLOYED,>=|nan,-962 & NAME_FAMILY_STATUS,in|nan,('Civil marriage','Married') & DAYS_EMPLOYED,<,-430"
]
)
从策略报告策略分析报告v6.xlsx和策略分析报告v6.pdf中可以看到已经按预先定义的数结构完美的遍历了数据: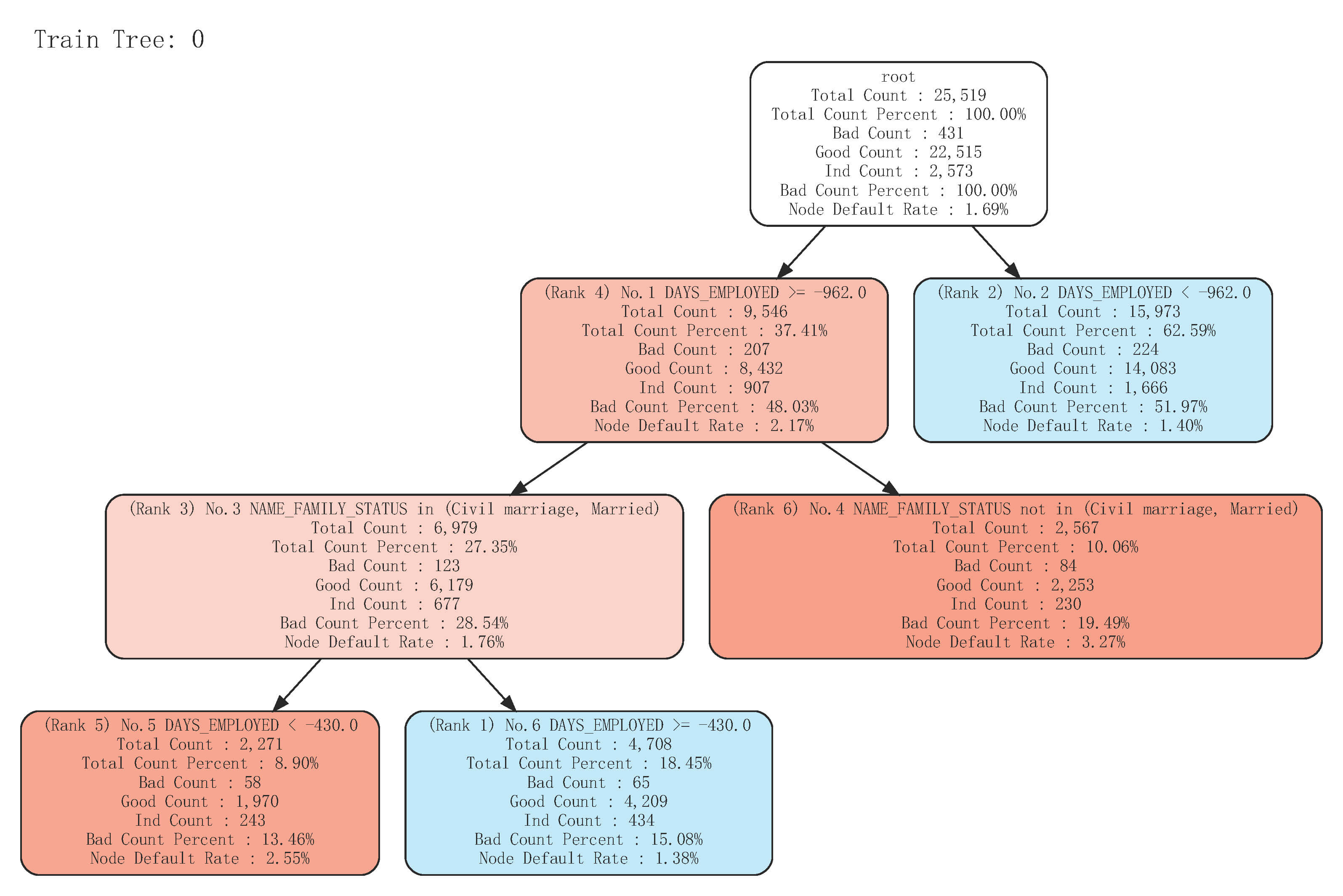
当然了,此时正负向的规则还是自动筛选的,再介绍一下如何指定节点为正负规则,
- 入参为
dict,分两个key,分别为negative和positive,代表负向和正向,value也是dict,如{"negative": {...}; "positive": {...}} - 负向和正向的
value中入参的dict,按树结构的key和树结构的节点组成的list构成,比如:{"negative": {"0": [4, 5]}} - 树结构节点的顺序为从上到下、从左到右依次增加
同时指定树结构和规则节点的样例如下:
at.Analysis.tree_flow(
df_train, "./策略分析demo/v7/v7.xlsx", test_data=df_test,
# 目标定义 & 切片定义
response="target",
split_col_name="birth_year", use_train_time=True,
exclude_column=["ID", "DAYS_BIRTH"], # 多变量分析时,DAYS_BIRTH会干扰Age的分析
add_info="ID", # 主键添加
customized_rule=[
"DAYS_EMPLOYED,>=|nan,-962 & NAME_FAMILY_STATUS,in|nan,('Civil marriage','Married') & DAYS_EMPLOYED,<,-430"
],
customized_nodes_dict={
"negative": {"0": [4, 5]}, "positive": {"0": [2, 6]}
}
)
这样就能在报告策略分析报告v7.xlsx的规则评估 - 正向规则 - 汇总和规则评估 - 负向规则 - 汇总两页看到指定的节点做为规则集的方式呈现: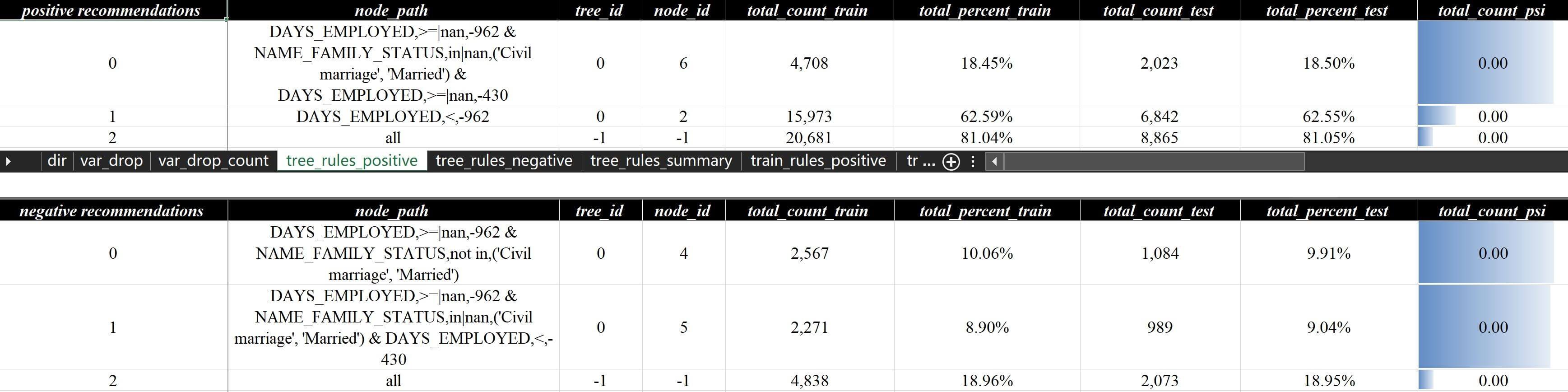
同时每类规则都会自动添加一行all来展示规则集的整体命中情况,这四条规则加一起其实是100%,现实中当然不会这样选,这里只是做为案例演示,也可以通过参考自动生成的配置文件中的customized_rule和customized_nodes_dict来学习如何正确入参
- 入参
customized_rule时,此时allow_nan和allow_discrete不会随model_type_path自动变化,比如不希望支持nan,或不想规则自动补全|nan,则需要手动把allow_nan调整为False - 入参
customized_rule时,可以支持response为None的无监督测算,不过此时只能测算一些基本的分布,当然customized_rule和response同时为None是不支持的 - 因为3.1.4 继承已有模型的存在,
model_exists优先级高于customized_rule,两者同时入参时,会从model_exists中解析出规则覆盖customized_rule,因此仅在model_exists和customized_rule都为None时才开启新模型训练流程 - 又因为3.1.2 自定义变量的存在,
customized_rule优先级会高于customized_variables,两个参数同时入参前者会覆盖后者 - 如果
customized_rule为空,则入参的customized_nodes_dict会被重置,前者优先级高于后者,两者都入参时需要有内在的关联关系,关联关系不正确的节点会在运行时删除 - 入参正确的
customized_nodes_dict后,不再进行规则自动搜索,因此会跳过下文中的3.2.2.1 基于有效性搜索和3.2.2.2 基于稳定性过滤
3.2.2 自动策略搜索
除了可手动定义外,默认是开启自动规则筛选模式的,参数如下:
# 自动规则筛选
# auto_nodes_flow 选填,默认True,是否基于规则自动搜索正负项节点主要也是基于有效性的搜索和基于稳定性的筛选,这两步有先后关系
3.2.2.1 基于有效性搜索
首先看基于有效性的搜索模式,参数如下:
# 自动规则筛选
# limit_rule_lift 选填,默认{},入参positive/negative:num使用
# limit_rule_number 选填,默认{},入参positive/negative:num使用
# limit_rule_percent 选填,默认0.0,规则筛选时,百分比上限
# nodes_rank_approach 选填,默认"weighted_lift",可选"lift"
# nodes_rank_percentile 选填,默认0.5,按排序选取百分比的量
# positive_negative_lift 选填,默认1.0,分割不同规则lift点- 首先按
nodes_rank_approach定义lift的内容,默认会按占比缩放权重 - 然后把模型树所有的规则都展开,按
positive_negative_lift根据每条规则的lift的取值自动分割出positive和negative两大类规则 - 然后对每类规则分别排序,排序后按
nodes_rank_percentile保留前百分比数量的规则 - 经过参数
limit_rule_percent确认搜索得到的规则的百分比占比符合要求 - 如果有定义
limit_rule_number,则按排序取对应的前N条规则 - 如果有定义
limit_rule_lift,则按lift阈值对应筛选规则
3.2.2.2 基于稳定性过滤
经过有效性搜索的规则会继续进行稳定性过滤,参数如下:
# 训练数据稳定性相关
# select_train_base 选填,默认"min",可选"max"或自定义基准
# eval_train_stable 选填,默认False,是否评估训练数据稳定性
# lift_gap_ratio_train 选填,默认0.1,训练数据lift最大偏移上限
# gini_gap_ratio_train 选填,默认0.1,训练数据gini最大偏移上限
# mean_cross_psi_train 选填,默认0.1,训练数据psi平均偏移上限值
# max_percent_gap_train 选填,默认0.1,训练占比的差值筛选的上限值
# 测试数据稳定性相关
# select_test_base 选填,默认"min",可选"max"或自定义基准
# eval_test_stable 选填,默认False,是否评估测试数据稳定性
# lift_gap_ratio_test 选填,默认0.1,测试数据lift最大偏移上限
# gini_gap_ratio_test 选填,默认0.1,测试数据gini最大偏移上限
# mean_cross_psi_test 选填,默认0.1,测试数据psi平均偏移上限值
# max_percent_gap_test 选填,默认0.1,测试占比的差值筛选的上限值
# 训练测试数据稳定性相关
# eval_cross_stable 选填,默认False,评估训练测试稳定性
# lift_gap_train_test 选填,默认0.1,测试数据lift偏移绝对值
# gini_gap_train_test 选填,默认0.1,训练测试gini偏移绝对值
# train_test_total_psi 选填,默认0.1,训练测试整体对比筛选psi
# train_test_cross_psi 选填,默认0.1,训练测试切片对比平均psi
# max_percent_gap_total 选填,默认0.1,训练测试整体占比偏移上限
# max_percent_gap_cross 选填,默认0.1,训练测试切片占比偏移上限
# train_test_lift_gap_ratio 选填,默认0.1,训练测试数据的lift偏移上限
# train_test_gini_gap_ratio 选填,默认0.1,训练测试数据的gini偏移上限这一部分与零基础实现高质量数据挖掘(数据分析篇)- 4.5 稳定性筛选有一定的相似度,默认也是不开启过滤,主要稳定性影响的因素太多了
3.3 策略重合度分析
重合度分析相关的参数有:
# 重合度分析
# merge_customized_nodes 选填,默认True,合并分析同类节点
# analysis_nodes_duplicates 选填,默认True,分析规则间重合度
# max_nodes_duplicates_value 选填,默认30,重合分析规则上限数参数merge_customized_nodes会在规则集最后插入一条all的数据来评估规则集在数据集整体上的命中情况,如3.2.1 手动定义规则中的案例,而参数analysis_nodes_duplicates会生成规则之间的重合度,比如策略分析报告v1-lgb.xlsx的规则评估 - 正向分布重合度 - 开发页面: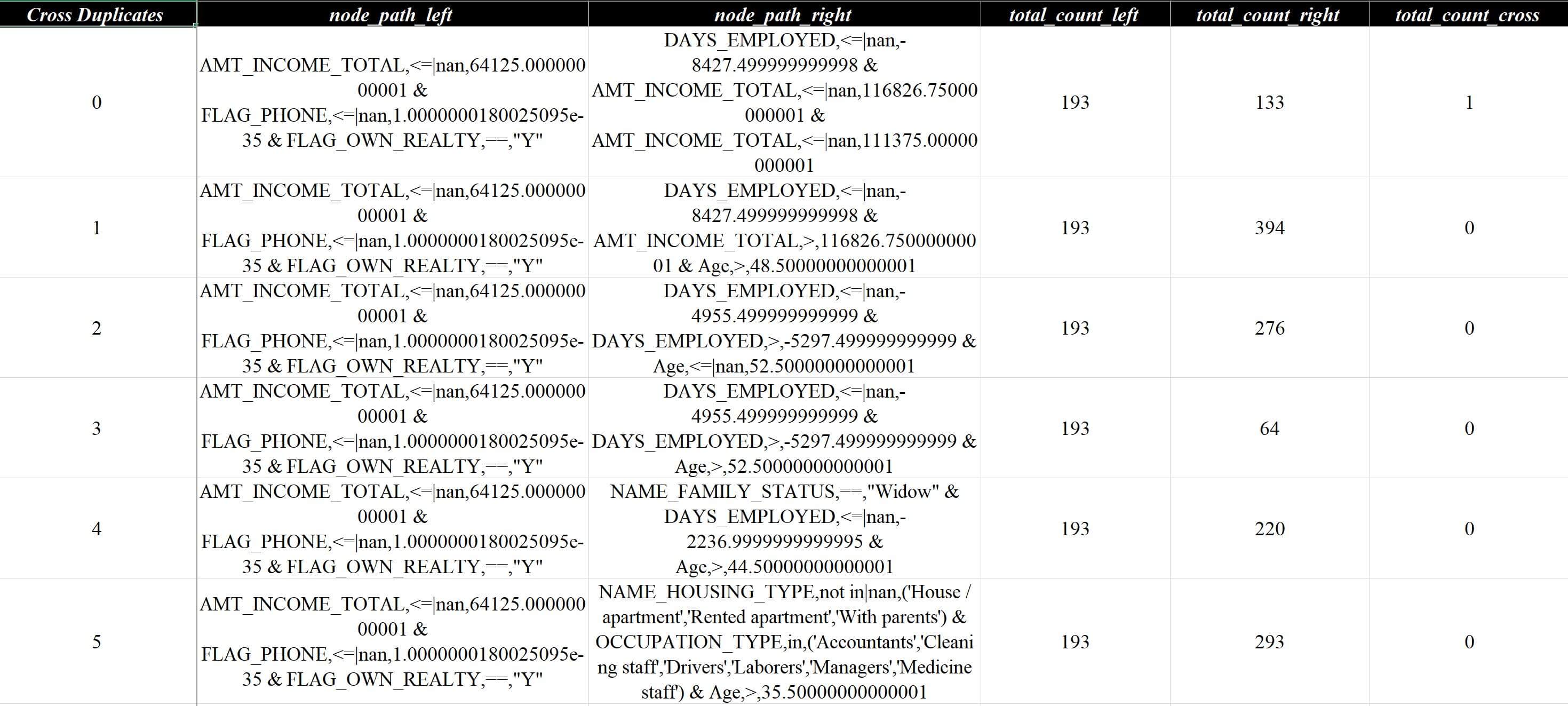
这个分析是穷举所有规则两两间的重合度,复杂度比较高,因此有max_nodes_duplicates_value参数限制复杂度
3.4 策略交叉矩阵分析
有些场景下,会同时存在一些交叉分析的需求,提供的参数有:
# 交叉矩阵分析
# maximum_node_item 选填,默认9,最大支持node_item的数量,过多会导致性能问题
# node_length_limit 选填,默认30,限制node名称和离散值个数长度,避免绘图异常
# node_cut_range 选填,默认{},数值node的自定义分组,格式{var: range}
# node_cut_part 选填,默认5,等量分组数,优先级低于node_cut_range
# node_info 选填,默认None,需要交叉分析的列,数值会预分箱比如我需要同时了解不同规则命中客群的年龄差异和分布等,则案例如下:
at.Analysis.tree_flow(
df_train, "./策略分析demo/v8-lgb/v8-lgb.xlsx", test_data=df_test,
# 目标定义 & 切片定义
response="target", split_col_name="birth_year", use_train_time=True,
exclude_column=["ID", "DAYS_BIRTH"], # 多变量分析时,DAYS_BIRTH会干扰Age的分析
add_info="ID", # 主键添加
node_info="Age"
)
从报告策略分析报告v8-lgb.xlsx和策略分析报告v8-lgb.pdf可以看到多了很多与Age相关的信息: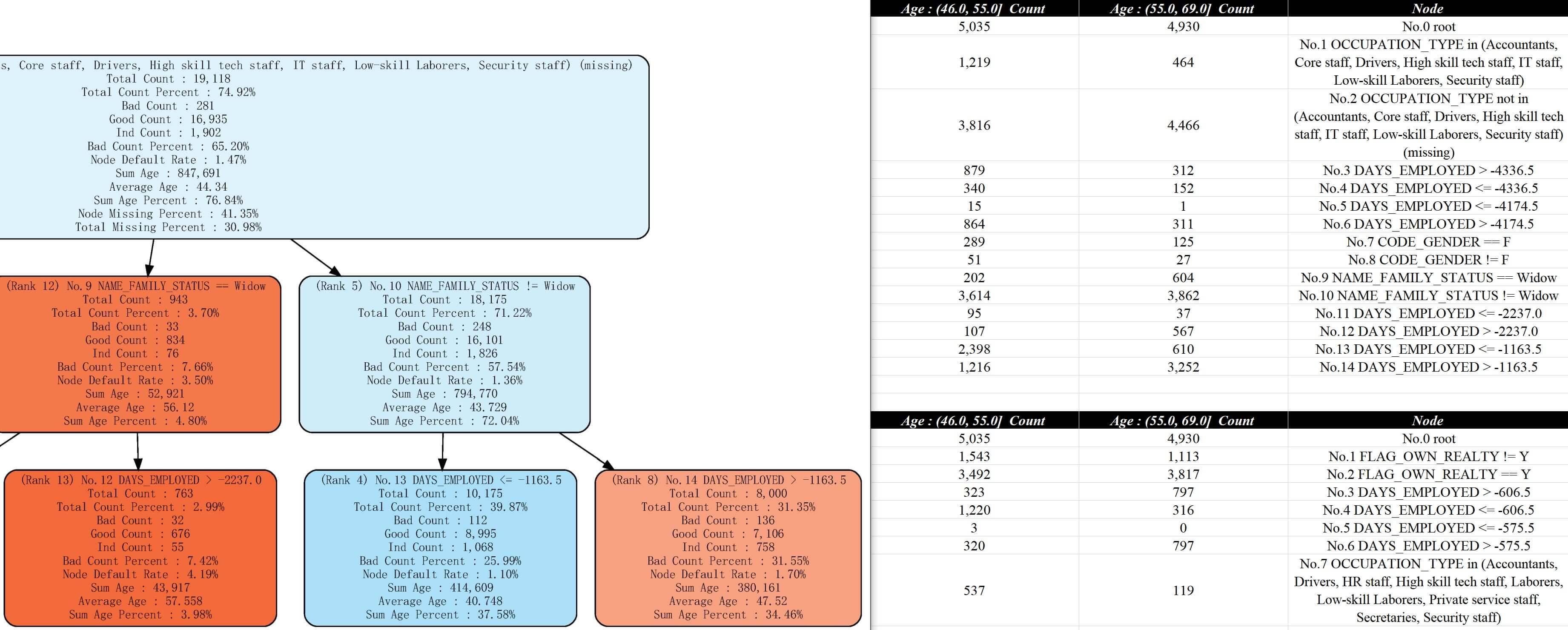
可以通过参数node_cut_range和node_cut_part调整数值变量的分箱,同时支持离散值,在涉及到一些策略细化、客群对比、决策权衡等问题时会有额外的帮助
4 报告和数据输出
4.1 报告格式调整
参数与零基础实现高质量数据挖掘(数据分析篇)- 6.1 报告格式调整一样:
输出文档
数据分析报告v12.xlsx中的大量格式和颜色都是可以进行修改的,涉及到的自动格式调整参数如下:# 自动格式调整 # add_excel_table_dir 选填,默认True,给输出的excel表格自动添加目录 # train_test_dir_cn 选填,默认None,即["开发", "验证"],train和test中文 # deal_unused_input 选填,默认"error",处理无效入参的方式,可选"warning" # text_wrap_trigger 选填,默认36,在auto_formatting时对超过长度的单元格自动换行 # auto_formatting 选填,默认True,自动添加条件格式、设置单元格格式、添加表头格式 # data_bar_cols 选填,默认["rate", "woe", "corr"],条件格式的列,支持str或list # format_header 选填,默认True,自定义输出表的表头格式,参数通过查看__header__来更改 # hidden_tables 选填,默认None,自定义输出文件中,需要隐藏的表格的名称,支持str或list # hidden_cols 选填,默认["var_name", "var_new"],输出多表格时自动隐藏的列,支持str或list主要包含:自动目录添加、入参校验、自动条件格式、长文本自动换行,自动单元格格式、自动生成数据栏、自动隐藏不必要的表和列等,
同时也支持手动修改默认表格输出的参数,默认参数在
at.dt.__excel__这个位置可见:正常情况下无需修改,如无必要不建议修改,不恰当的入参可能会引发意料之外的报错
主要参数完全一致,除以下两项默认值不同:
# data_bar_cols 选填,默认["rate", "importance", "gain", "psi"],自动添加条件格式
# hidden_cols 选填,默认None,输出多表格时自动隐藏的列,支持str或list,本模块无默认值全局参数位置改成at.tt.__excel__,同样也不建议调整
4.2 数据文件输出
与零基础实现高质量数据挖掘(数据分析篇)- 6.2 数据文件输出中类似,不仅仅会输出csv文件,还会输出策略部署的代码,包括sql和pmml等,
# 文件输出相关
# save_children_nodes 选填,默认False,导出模型使用的树结构的命中节点到文件
# save_children_proba 选填,默认False,导出融合模型的子模型的概率到csv文件
# save_raw_dataframe 选填,默认False,输出输入数据的筛选原始数据到csv文件
# save_proba_value 选填,默认False,导出模型的预测的概率的结果到csv文件
# save_model_pmml 选填,默认True,使用sklearn2pmml来转化模型为pmml模型
# use_rule_proba 选填,默认False,为True时总是使用规则来进行概率预测
# save_model_pkl 选填,默认True,将计算的模型的结果存储为pkl文件导出
# save_or_return 选填,默认True,False会缓存在__data__对应区域
# save_tree_sql 选填,默认True,解析并导出树结构对应的sql文件
# save_json 选填,默认True,将计算结果配置文件输出为json
# add_info 选填,默认None,添加的列,支持str和list- 本模块集中在策略的筛选、规则集的测算和应用上,参数
save_proba_value和save_children_proba需要谨慎使用的,因为当存在模型训练时会倾向使用模型本身的predict_proba来预测概率,当没有模型仅存在规则时会使用开发数据集的实际命中情况来预测 - 可以通过把
use_rule_proba调整为True来实现总是使用数据集规则的概率预测,但此时和pmml文件输出的概率并不一致,因此也不建议直接部署pmml文件,本模块目的还是以策略展开为准,确实需要模型测算请使用model_tools - 概率输出区分方式上,
csv文件中"_model"结尾或"_模型class名称"结尾的列为模型预测取值概率值,"_weight"结尾或"_树结构key"结尾的列则是规则预测的概率值
除常规文件输出外,还涉及绘图报告输出参数如下:
# 绘图输出相关
# maximum_drawing_items 选填,默认300,最大绘图项的个数,超出则关闭绘图相关的输出
# save_merge_graph_pdf 选填,默认True,当存在多个绘图时,自动合并绘图到pdf文件
# lock_merge_graph_pdf 选填,默认False,当合并多个绘图时,是否加密最终输出文件
# save_svg_file 选填,默认False,解析并导出对应的svg文件
# save_pdf_file 选填,默认True,解析并导出对应的pdf文件
# save_gv_file 选填,默认False,解析并导出对应的gv文件另外关于绘图报告中的着色和绘图内容,可调整的参数有:
# 绘图内容相关
# draw_lift_gini_entropy 选填,默认False,输出每个节点对应的entropy和gini值
# max_label_length 选填,默认30,绘图时标题单行的最大长度,会自动换行
# fill_auto_color 选填,默认True,自动为输出的绘图计算并添加梯度颜色
# use_train_color 选填,默认True,默认测试使用训练配色,否则独立绘图
# draw_rank_num 选填,默认True,默认在配色状态下,标记节点排序信息
# include_right 选填,默认True,数值分组时的边界,True时包含右侧值
# precision 选填,默认3,处理数据过程中,保留的小数点数
# root_desc 选填,默认"root",可视化图表中根节点的描述此处一般root_desc调整的多一些,可以让输出的pdf的根节点描述更自然
- 绘图需要提前安装
graphviz,可以访问https://graphviz.org/download/下载执行,linux可以使用类似apt install graphviz来安装,或者直接conda install graphviz也行 - 除
graphviz软件本身,还需要套一层python的调用接口,这个在python环境管理部分中的requirements.txt已经包含 - 中文字体安装部分也是必须的,不然中文部分会乱码
4.3 配置映射和还原
只看参数和用法的话,与零基础实现高质量数据挖掘(数据分析篇)- 6.3 配置映射和还原是基本一致的:
除了常规输出的
csv和xlsx文件外,还会输出配置文件json和pkl,用来避免配置文件的重复输入,涉及的主要参数有:# 从配置文件还原 # recover_from_json 选填,默认None,输入对应的.json文件来从对应的json映射结果 # recover_from_pkl 选填,默认True,默认从pkl完整映射上次计算结果,overwrite时失效 # overwrite_json 选填,默认False,使运行时的入参设置覆盖读取的json文件的对应设置例如之前
数据分析报告v12.xlsx搭配的配置文件有Data_v12.json和Data_v12_data.pkl,如果打开可以看到里面主要都是之前定义的参数和分析过程中的缓存对象:配置文件的主要使用方式举例如下:
at.Analysis.data_flow( df_train, "./数据分析demo/v12-rec/v12-rec.xlsx", test_data=df_test, recover_from_json="./数据分析demo/v12/Data_v12.json" )从配置文件还原 从结果文件
数据分析报告v12-rec.xlsx来看,和之前数据分析报告v12.xlsx效果相同的情况下,节省了很多笔墨配置恢复备注
- 参数
recover_from_pkl用在仅100%恢复之前的配置文件,且不进行覆写调整的场景下使用- 有效使用
recover_from_pkl时,不再会经过判断和过滤,因此不生成变量评估 - 排除详情页面- 如果需要基于配置文件进行调整,不建议修改
json文件(可能会打破json与pkl文件之间的数据关联),推荐直接入参需要调整的参数- 只要覆写入参和之前不同,就会自动启用
overwrite_json,但只有当判定覆写入参影响训练结果时,才会自动禁用recover_from_pkl,此时并非100%还原历史数据,而是基于当下数据和历史配置重新训练- 当
overwrite_json的对象为list时,且入参为"add_info"或"node_info"时,会对参数进行合并去重而不是覆写- 当
overwrite_json的对象为dict时,进行update操作而不是覆写- 一开始自定义的
customized_groups除非入参覆盖不然都会还原,由算法生成入参的customized_groups会在判定覆写入参影响训练结果时被替换为重新训练以后的值
差异点在于不需要通过pkl文件恢复规则,因此recover_from_pkl实质上弃用了:
# recover_from_pkl 选填,默认True,规则恢复不需要通过pkl文件,在本模块中为无效参数和data_flow的处理逻辑类似,整体用例如下:
at.Analysis.tree_flow(
df_train, "./策略分析demo/v1-rec/v1-rec.xlsx", test_data=df_test,
recover_from_json="./策略分析demo/v1-lgb/Tree_v1-lgb.json"
)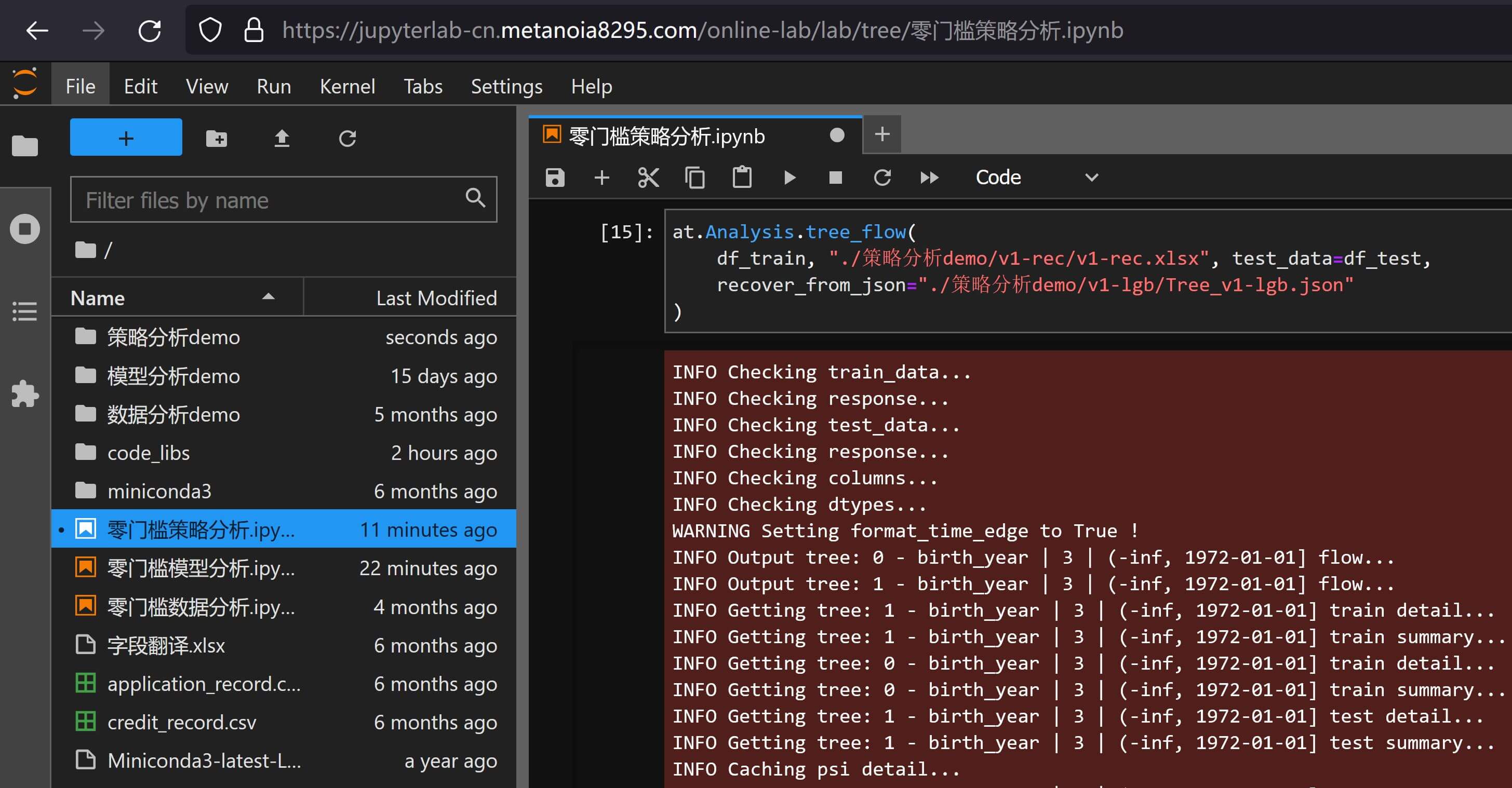
得到策略分析报告策略分析报告v1-rec.xlsx,不过需要注意4.2 数据文件输出中提到的概率输出问题
4.4 多数据映射和还原
此部分与零基础实现高质量数据挖掘(数据分析篇)- 6.4 多数据映射和还原的架构一致:
在上面6.3 配置映射和还原这节中介绍了配置文件的还原,但是如2.5 多数据映射所述,现实使用时情况会比较复杂,这里再介绍一下多数据映射情况下的还原方式,主要参数如下:
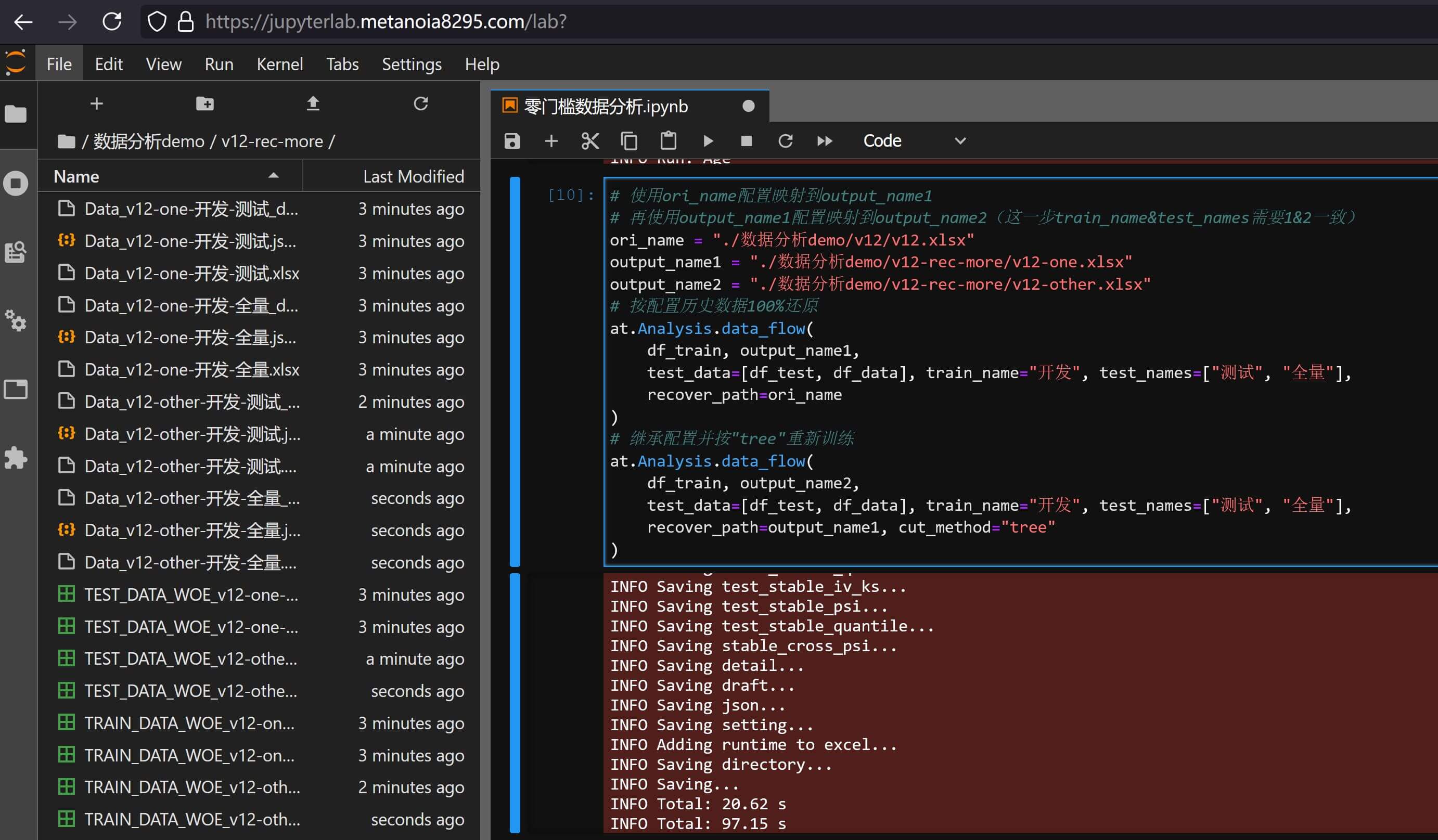
# alpha_tools.Analysis参数 # recover_path 选填,默认None,入参str需要以.xlsx结尾,根据输出文件还原json和pkl配置 # recover_search 选填,默认True,按train_name和test_names入参联动调整recover_path路径取值 # only_recover_json 选填,默认False,在使用recover_path还原时是否忽略pkl,只按json文件还原配置这里来看一个稍微复杂的案例,其中
output_name2处与直接修改5.7 分箱搜索和过滤处的cut_method入参效果相同:# 使用ori_name配置映射到output_name1 # 再使用output_name1配置映射到output_name2(这一步train_name&test_names需要1&2一致) ori_name = "./数据分析demo/v12/v12.xlsx" output_name1 = "./数据分析demo/v12-rec-more/v12-one.xlsx" output_name2 = "./数据分析demo/v12-rec-more/v12-other.xlsx" # 按配置历史数据100%还原 at.Analysis.data_flow( df_train, output_name1, test_data=[df_test, df_data], train_name="开发", test_names=["测试", "全量"], recover_path=ori_name ) # 继承配置并按"tree"重新训练 at.Analysis.data_flow( df_train, output_name2, test_data=[df_test, df_data], train_name="开发", test_names=["测试", "全量"], recover_path=output_name1, cut_method="tree" ) # 打包结果 at.dt.Api.zip_dir_files("./数据分析demo/v12-rec-more.zip", "./数据分析demo/v12-rec-more")多数据映射与还原 这样就实现了多文件的映射与还原,打包文件详情可以自行下载
v12-rec-more.zip查看
除了参数only_recover_json会因为recover_from_pkl的失效而失效,样例如下:
ori_name = "./策略分析demo/v1-lgb/v1-lgb.xlsx"
new_output = "./策略分析demo/vr-lgb/vr-lgb.xlsx"
at.Analysis.tree_flow(
df_train, new_output,
test_data=[df_test, df_data], train_name="开发", test_names=["测试", "全量"],
recover_path=ori_name,
)
# 打包结果
at.dt.Api.zip_dir_files("./策略分析demo/vr-lgb.zip", "./策略分析demo/vr-lgb")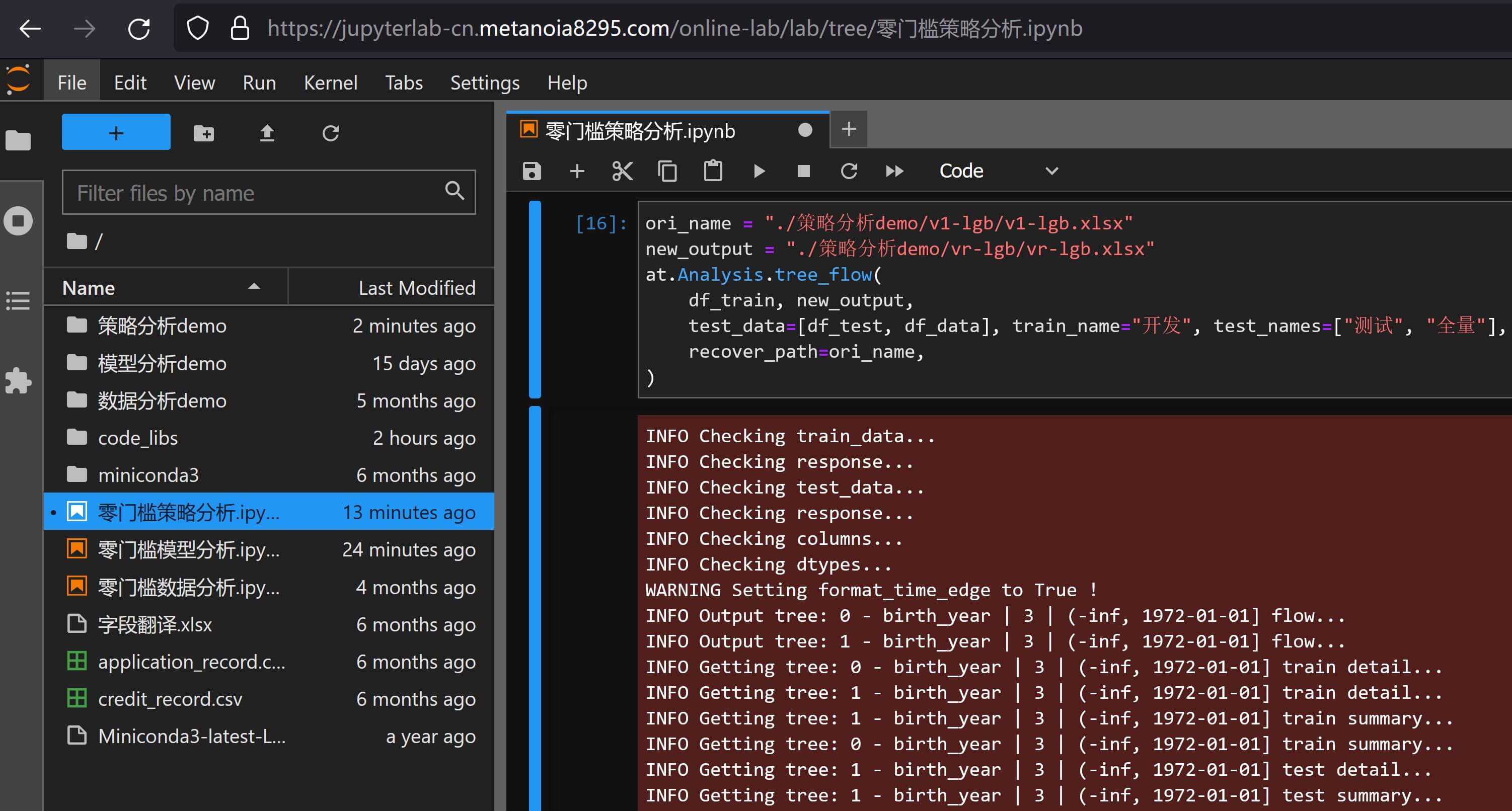
点击下载报告的压缩文件vr-lgb.zip查看详情
4.5 报告合并与数据合并
参考零基础实现高质量数据挖掘(数据分析篇)- 6.5 报告合并与数据合并中的说明:
在上面5.2 分箱算法和生成这节中,我们看到很多时候是需要横向对比多个报告的,因此存在针对多份报告和数据进行自动合并的需求,实现了既可以合并报告内的页面,也可以将各个分析的数据集移动并重命名到同一路径,主要通过以下两个函数实现:
报告合并函数说明 横向合并需要手动指定,比如之前5.2 分箱算法和生成这节中使用方式为:
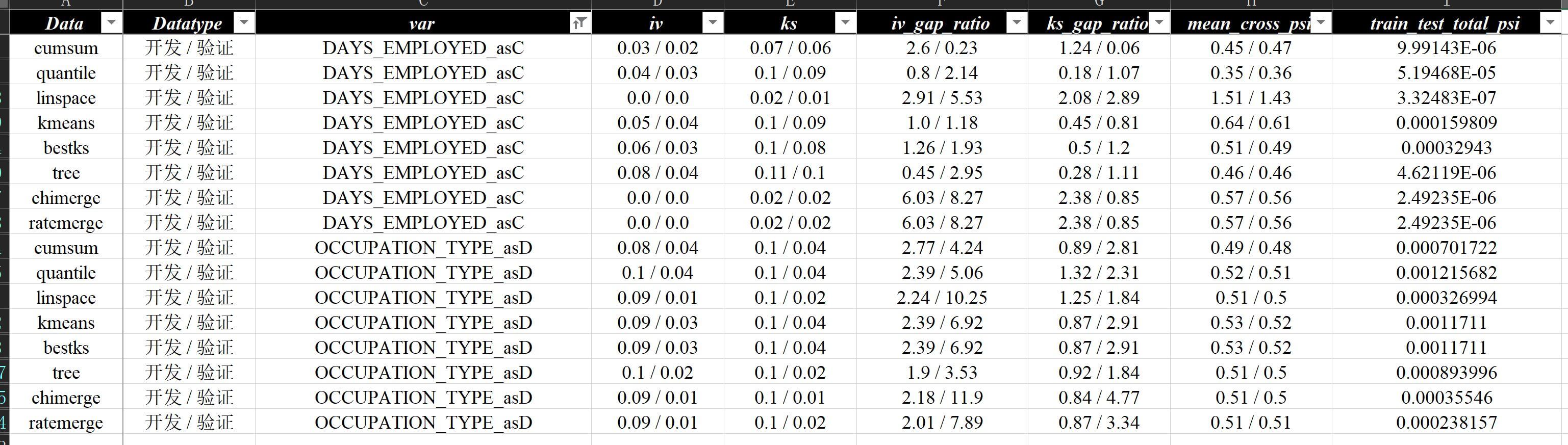
at.Report.create_data_report( "./数据分析demo/v9-算法对比/v9-算法对比.xlsx", [ "./数据分析demo/v9-cumsum/v9-cumsum.xlsx", "./数据分析demo/v9-quantile/v9-quantile.xlsx", "./数据分析demo/v9-linspace/v9-linspace.xlsx", "./数据分析demo/v9-kmeans/v9-kmeans.xlsx", "./数据分析demo/v9-bestks/v9-bestks.xlsx", "./数据分析demo/v9-tree/v9-tree.xlsx", "./数据分析demo/v9-chimerge/v9-chimerge.xlsx", "./数据分析demo/v9-ratemerge/v9-ratemerge.xlsx" ], ["cumsum", "quantile", "linspace", "kmeans", "bestks", "tree", "chimerge", "ratemerge"] )文件横向合并 最后得到的效果和对应的分析,也在5.2 分箱算法和生成这节中有所展示:
算法效果对比( DAYS_EMPLOYED、OCCUPATION_TYPE)而针对2.5 多数据映射和6.4 多数据映射和还原中提到的多数据情况,需要进行纵向合并,简单输入:
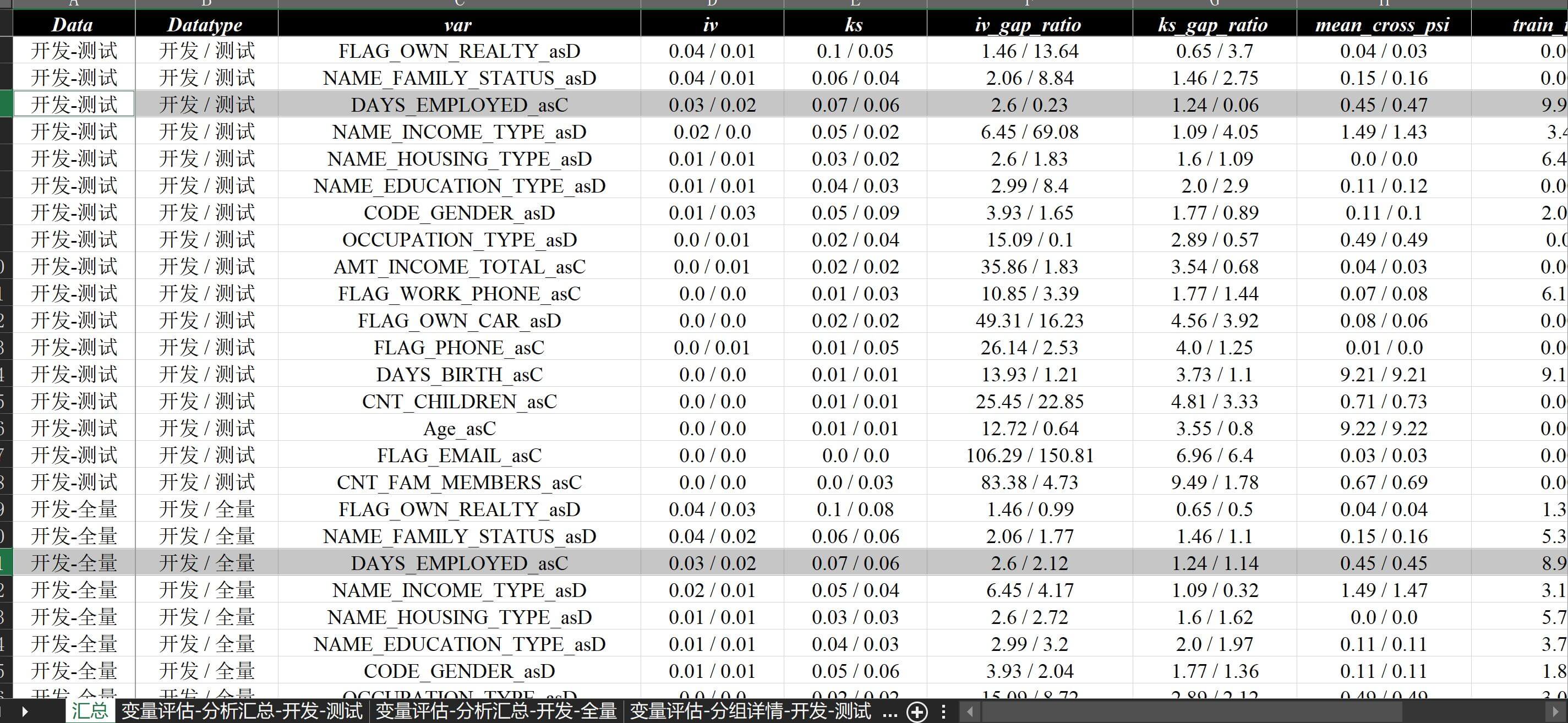
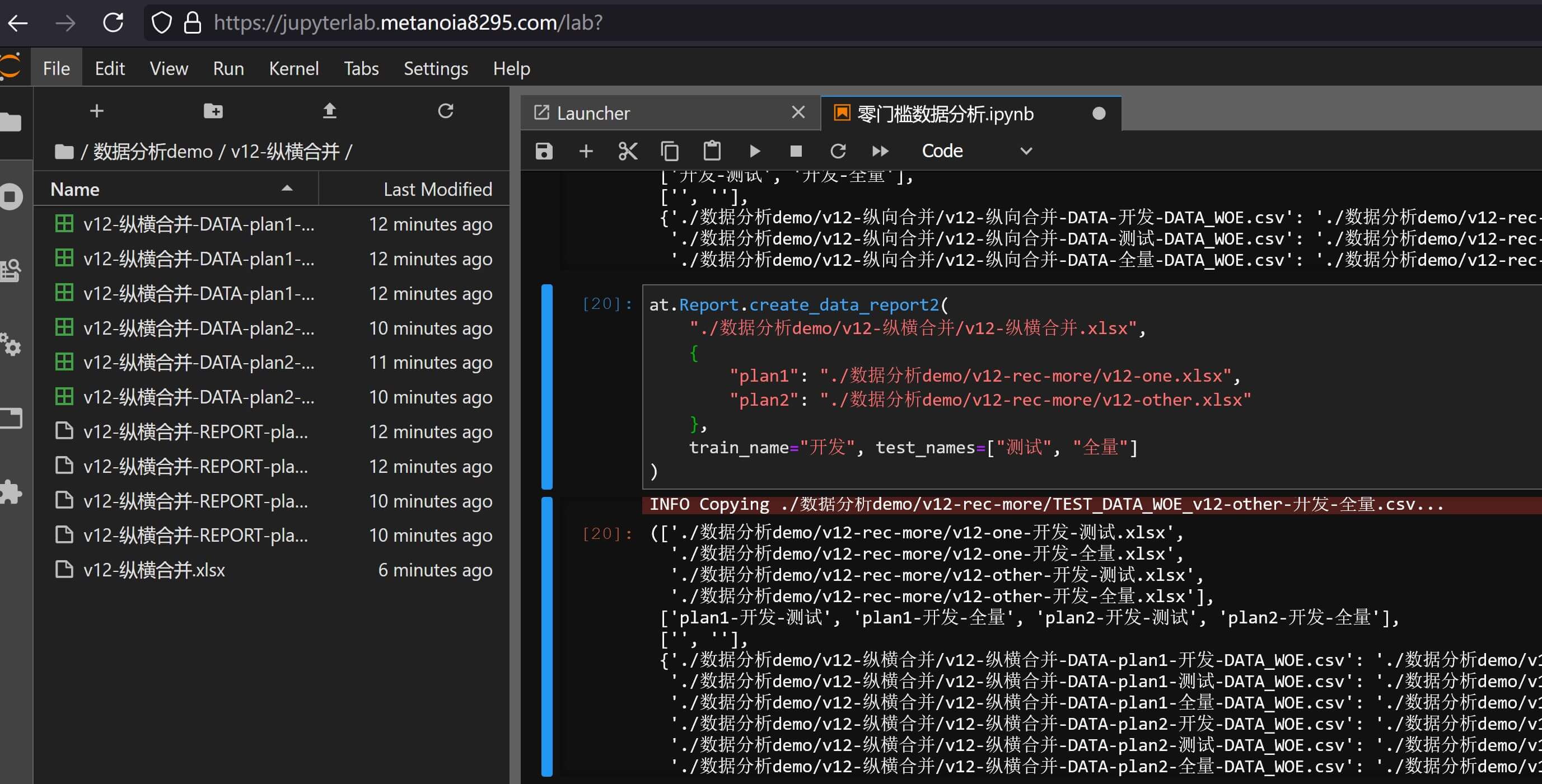
at.Report.create_data_report2( "./数据分析demo/v12-纵向合并/v12-纵向合并.xlsx", "./数据分析demo/v12-rec-more/v12-one.xlsx", train_name="开发", test_names=["测试", "全量"] )文件纵向合并 即可实现多数据映射层面的纵向文件合并,效果如下:
纵向合并效果示例 另外如果涉及到横向合并多个纵向数据集的报告,则可输入:
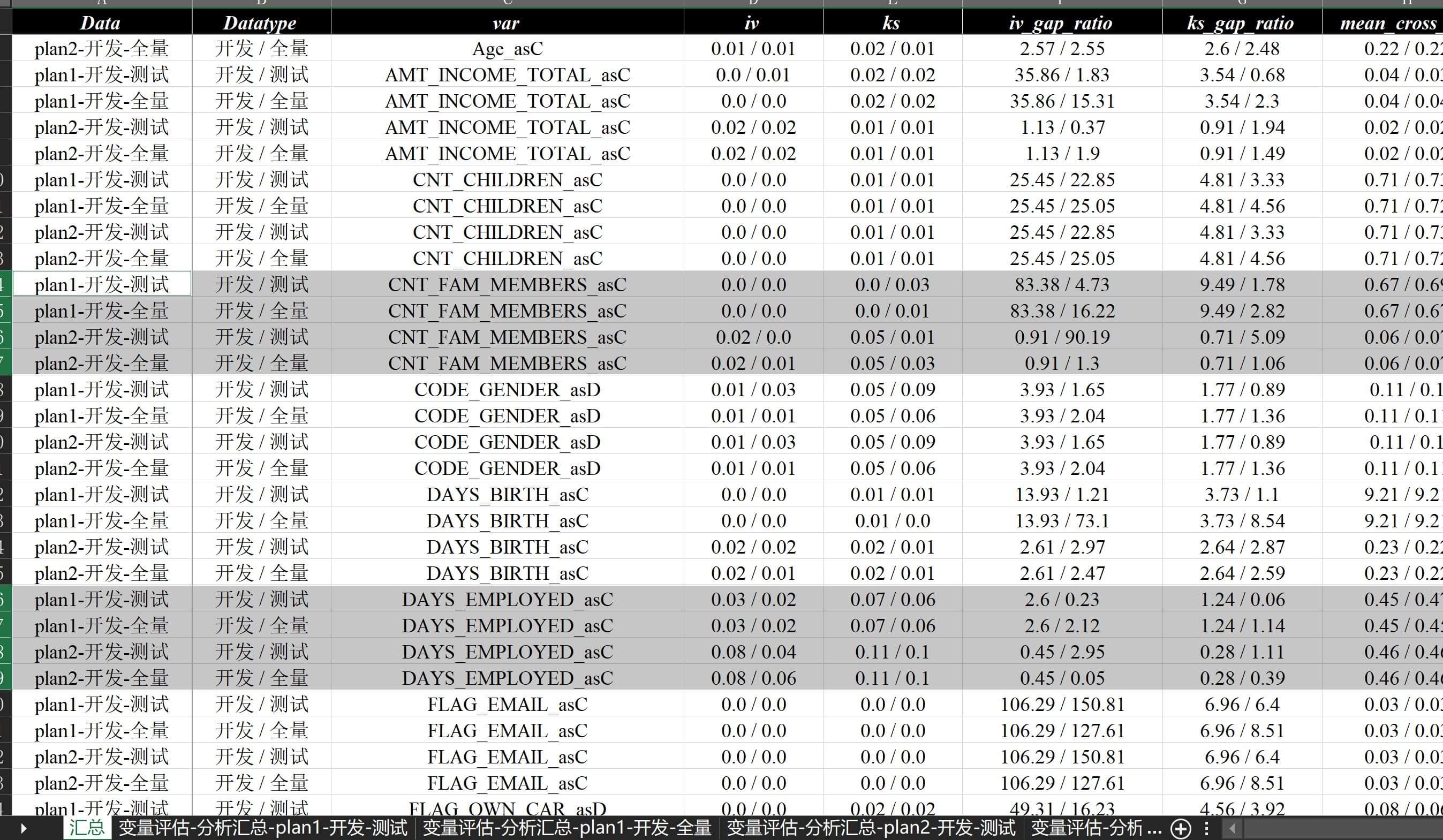
at.Report.create_data_report2( "./数据分析demo/v12-纵横合并/v12-纵横合并.xlsx", { "plan1": "./数据分析demo/v12-rec-more/v12-one.xlsx", "plan2": "./数据分析demo/v12-rec-more/v12-other.xlsx" }, train_name="开发", test_names=["测试", "全量"] )文件纵横合并 实现多方案多数据集综合交叉对比,排序后的效果截图如下:
纵横合并效果示例 简单来看,部分数据上
tree算法还是有些许提升效果的,小技巧
报告合并的
sheetname范围和csv搜索的范围均在在__excel__中定义如果是在
win环境下,会多一页附录,原理是使用pywin32调用excel把文件做为附件插入报告附录页( windows)最后附上以上三类报告合并的样例文件:
压缩输出合并文档
把create_data_report换成create_tree_report就行了,另外win下会把xlsx和pdf做为附件插入附录页,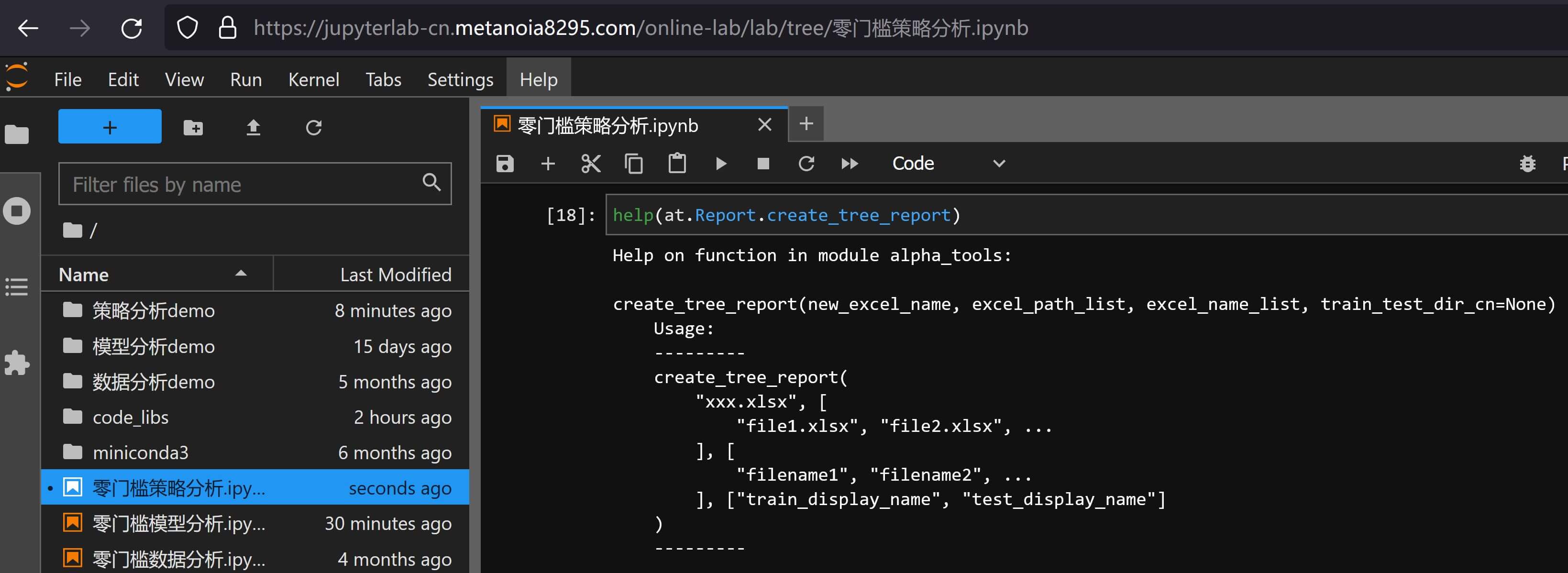
简单的合并案例如下:
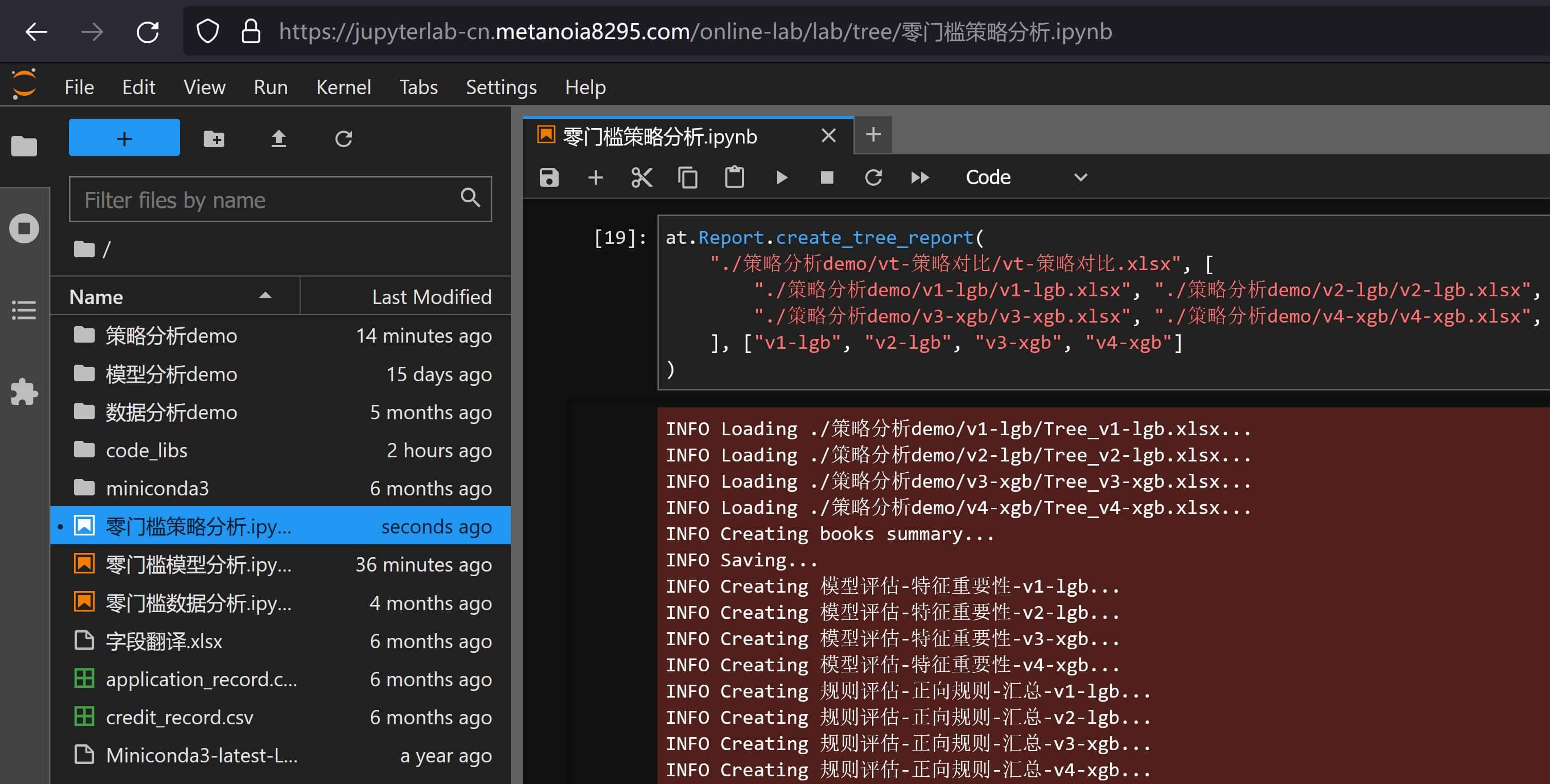
at.Report.create_tree_report(
"./策略分析demo/vt-策略对比/vt-策略对比.xlsx", [
"./策略分析demo/v1-lgb/v1-lgb.xlsx", "./策略分析demo/v2-lgb/v2-lgb.xlsx",
"./策略分析demo/v3-xgb/v3-xgb.xlsx", "./策略分析demo/v4-xgb/v4-xgb.xlsx",
], ["v1-lgb", "v2-lgb", "v3-xgb", "v4-xgb"]
)
稍微看一下合并以后的对比报告vt-策略对比.xlsx,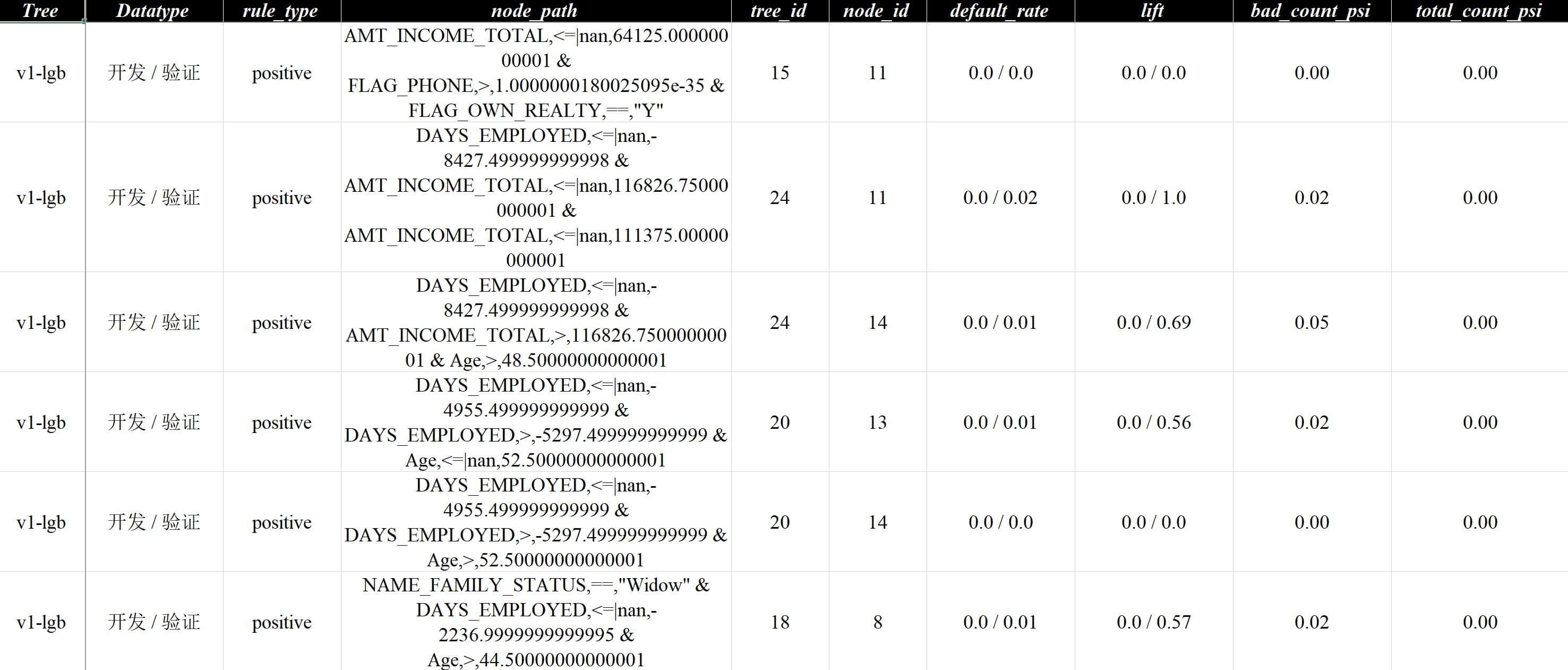
比较适合搭配关键字搜索横向比较等
5 总结
完整的工作簿:零门槛策略分析.ipynb,对应的html:零门槛策略分析.html,有兴趣请邮件或留言咨询